Jimmy Ming-Tai Wu, Min Wei, Mu-En Wu, Shahab Tayeb
{"title":"Top-<i>k</i> dominating queries on incomplete large dataset.","authors":"Jimmy Ming-Tai Wu, Min Wei, Mu-En Wu, Shahab Tayeb","doi":"10.1007/s11227-021-04005-x","DOIUrl":null,"url":null,"abstract":"<p><p>Top-<i>k</i> dominating (TKD) query is one of the methods to find the interesting objects by returning the <i>k</i> objects that dominate other objects in a given dataset. Incomplete datasets have missing values in uncertain dimensions, so it is difficult to obtain useful information with traditional data mining methods on complete data. BitMap Index Guided Algorithm (BIG) is a good choice for solving this problem. However, it is even harder to find top-<i>k</i> dominance objects on incomplete big data. When the dataset is too large, the requirements for the feasibility and performance of the algorithm will become very high. In this paper, we proposed an algorithm to apply MapReduce on the whole process with a pruning strategy, called Efficient Hadoop BitMap Index Guided Algorithm (EHBIG). This algorithm can realize TKD query on incomplete datasets through BitMap Index and use MapReduce architecture to make TKD query possible on large datasets. By using the pruning strategy, the runtime and memory usage are greatly reduced. What's more, we also proposed an improved version of EHBIG (denoted as IEHBIG) which optimizes the whole algorithm flow. Our in-depth work in this article culminates with some experimental results that clearly show that our proposed algorithm can perform well on TKD query in an incomplete large dataset and shows great performance in a Hadoop computing cluster.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"78 3","pages":"3976-3997"},"PeriodicalIF":2.5000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s11227-021-04005-x","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-021-04005-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/8/17 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
引用次数: 5
Abstract
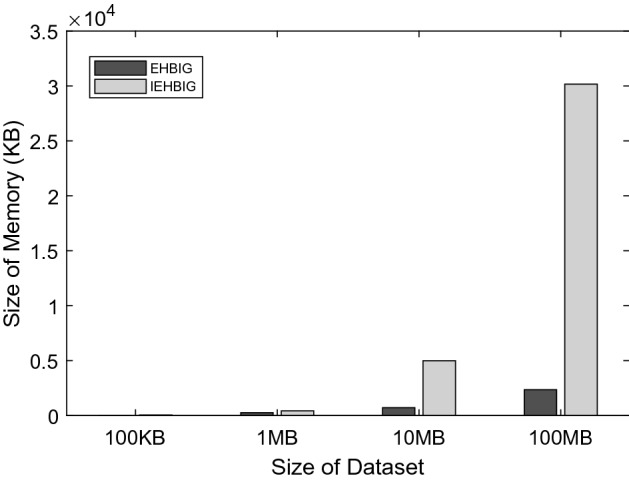
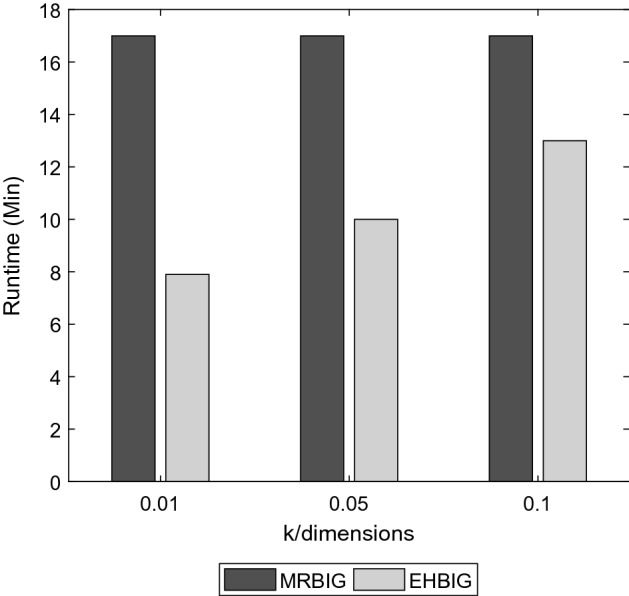
Top-k dominating (TKD) query is one of the methods to find the interesting objects by returning the k objects that dominate other objects in a given dataset. Incomplete datasets have missing values in uncertain dimensions, so it is difficult to obtain useful information with traditional data mining methods on complete data. BitMap Index Guided Algorithm (BIG) is a good choice for solving this problem. However, it is even harder to find top-k dominance objects on incomplete big data. When the dataset is too large, the requirements for the feasibility and performance of the algorithm will become very high. In this paper, we proposed an algorithm to apply MapReduce on the whole process with a pruning strategy, called Efficient Hadoop BitMap Index Guided Algorithm (EHBIG). This algorithm can realize TKD query on incomplete datasets through BitMap Index and use MapReduce architecture to make TKD query possible on large datasets. By using the pruning strategy, the runtime and memory usage are greatly reduced. What's more, we also proposed an improved version of EHBIG (denoted as IEHBIG) which optimizes the whole algorithm flow. Our in-depth work in this article culminates with some experimental results that clearly show that our proposed algorithm can perform well on TKD query in an incomplete large dataset and shows great performance in a Hadoop computing cluster.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


