Alistair E W Johnson, Lucas Bulgarelli, Tom J Pollard
{"title":"Deidentification of free-text medical records using pre-trained bidirectional transformers.","authors":"Alistair E W Johnson, Lucas Bulgarelli, Tom J Pollard","doi":"10.1145/3368555.3384455","DOIUrl":null,"url":null,"abstract":"<p><p>The ability of caregivers and investigators to share patient data is fundamental to many areas of clinical practice and biomedical research. Prior to sharing, it is often necessary to remove identifiers such as names, contact details, and dates in order to protect patient privacy. Deidentification, the process of removing identifiers, is challenging, however. High-quality annotated data for developing models is scarce; many target identifiers are highly heterogenous (for example, there are uncountable variations of patient names); and in practice anything less than perfect sensitivity may be considered a failure. As a result, patient data is often withheld when sharing would be beneficial, and identifiable patient data is often divulged when a deidentified version would suffice. In recent years, advances in machine learning methods have led to rapid performance improvements in natural language processing tasks, in particular with the advent of large-scale pretrained language models. In this paper we develop and evaluate an approach for deidentification of clinical notes based on a bidirectional transformer model. We propose human interpretable evaluation measures and demonstrate state of the art performance against modern baseline models. Finally, we highlight current challenges in deidentification, including the absence of clear annotation guidelines, lack of portability of models, and paucity of training data. Code to develop our model is open source, allowing for broad reuse.</p>","PeriodicalId":87342,"journal":{"name":"Proceedings of the ACM Conference on Health, Inference, and Learning","volume":"2020 ","pages":"214-221"},"PeriodicalIF":0.0000,"publicationDate":"2020-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/e7/a6/nihms-1679580.PMC8330601.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proceedings of the ACM Conference on Health, Inference, and Learning","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1145/3368555.3384455","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/4/2 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
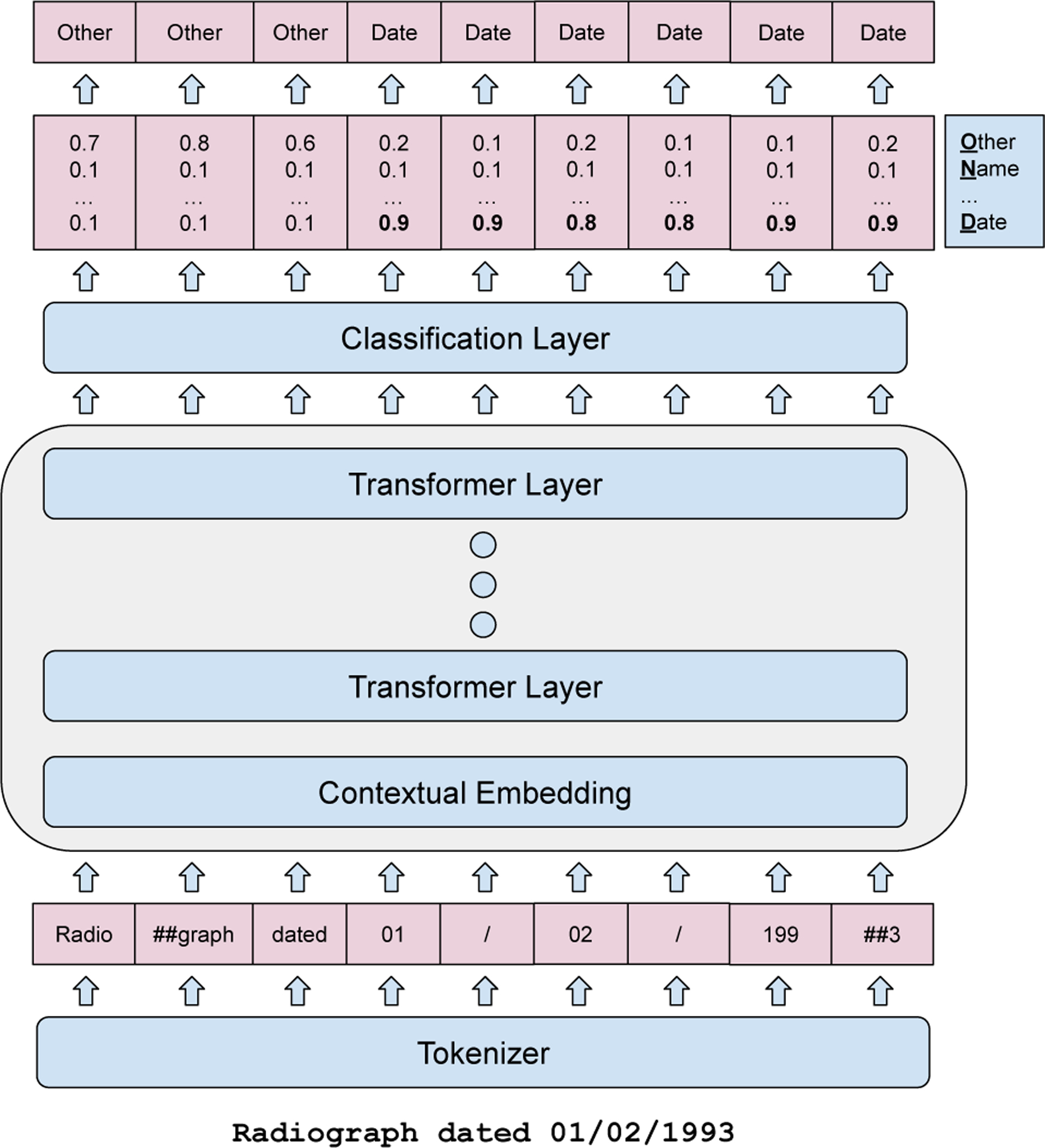
The ability of caregivers and investigators to share patient data is fundamental to many areas of clinical practice and biomedical research. Prior to sharing, it is often necessary to remove identifiers such as names, contact details, and dates in order to protect patient privacy. Deidentification, the process of removing identifiers, is challenging, however. High-quality annotated data for developing models is scarce; many target identifiers are highly heterogenous (for example, there are uncountable variations of patient names); and in practice anything less than perfect sensitivity may be considered a failure. As a result, patient data is often withheld when sharing would be beneficial, and identifiable patient data is often divulged when a deidentified version would suffice. In recent years, advances in machine learning methods have led to rapid performance improvements in natural language processing tasks, in particular with the advent of large-scale pretrained language models. In this paper we develop and evaluate an approach for deidentification of clinical notes based on a bidirectional transformer model. We propose human interpretable evaluation measures and demonstrate state of the art performance against modern baseline models. Finally, we highlight current challenges in deidentification, including the absence of clear annotation guidelines, lack of portability of models, and paucity of training data. Code to develop our model is open source, allowing for broad reuse.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


