{"title":"Bayesian optimization with evolutionary and structure-based regularization for directed protein evolution.","authors":"Trevor S Frisby, Christopher James Langmead","doi":"10.1186/s13015-021-00195-4","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Directed evolution (DE) is a technique for protein engineering that involves iterative rounds of mutagenesis and screening to search for sequences that optimize a given property, such as binding affinity to a specified target. Unfortunately, the underlying optimization problem is under-determined, and so mutations introduced to improve the specified property may come at the expense of unmeasured, but nevertheless important properties (ex. solubility, thermostability, etc). We address this issue by formulating DE as a regularized Bayesian optimization problem where the regularization term reflects evolutionary or structure-based constraints.</p><p><strong>Results: </strong>We applied our approach to DE to three representative proteins, GB1, BRCA1, and SARS-CoV-2 Spike, and evaluated both evolutionary and structure-based regularization terms. The results of these experiments demonstrate that: (i) structure-based regularization usually leads to better designs (and never hurts), compared to the unregularized setting; (ii) evolutionary-based regularization tends to be least effective; and (iii) regularization leads to better designs because it effectively focuses the search in certain areas of sequence space, making better use of the experimental budget. Additionally, like previous work in Machine learning assisted DE, we find that our approach significantly reduces the experimental burden of DE, relative to model-free methods.</p><p><strong>Conclusion: </strong>Introducing regularization into a Bayesian ML-assisted DE framework alters the exploratory patterns of the underlying optimization routine, and can shift variant selections towards those with a range of targeted and desirable properties. In particular, we find that structure-based regularization often improves variant selection compared to unregularized approaches, and never hurts.</p>","PeriodicalId":50823,"journal":{"name":"Algorithms for Molecular Biology","volume":"16 1","pages":"13"},"PeriodicalIF":1.5000,"publicationDate":"2021-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13015-021-00195-4","citationCount":"5","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithms for Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-021-00195-4","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 5
Abstract
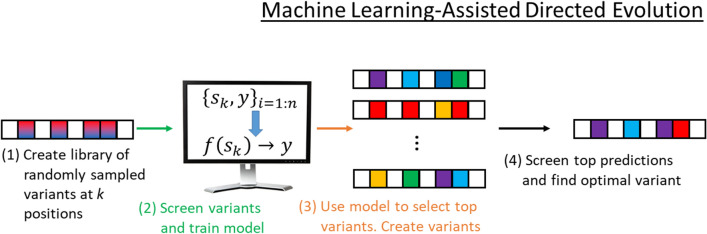
Background: Directed evolution (DE) is a technique for protein engineering that involves iterative rounds of mutagenesis and screening to search for sequences that optimize a given property, such as binding affinity to a specified target. Unfortunately, the underlying optimization problem is under-determined, and so mutations introduced to improve the specified property may come at the expense of unmeasured, but nevertheless important properties (ex. solubility, thermostability, etc). We address this issue by formulating DE as a regularized Bayesian optimization problem where the regularization term reflects evolutionary or structure-based constraints.
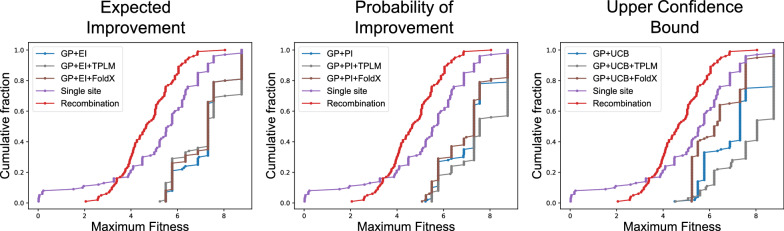
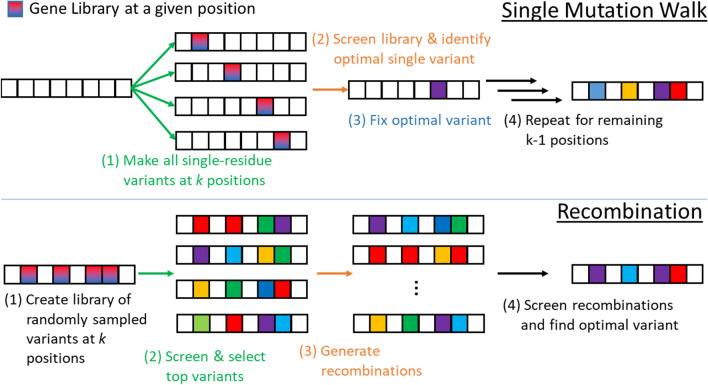
Results: We applied our approach to DE to three representative proteins, GB1, BRCA1, and SARS-CoV-2 Spike, and evaluated both evolutionary and structure-based regularization terms. The results of these experiments demonstrate that: (i) structure-based regularization usually leads to better designs (and never hurts), compared to the unregularized setting; (ii) evolutionary-based regularization tends to be least effective; and (iii) regularization leads to better designs because it effectively focuses the search in certain areas of sequence space, making better use of the experimental budget. Additionally, like previous work in Machine learning assisted DE, we find that our approach significantly reduces the experimental burden of DE, relative to model-free methods.
Conclusion: Introducing regularization into a Bayesian ML-assisted DE framework alters the exploratory patterns of the underlying optimization routine, and can shift variant selections towards those with a range of targeted and desirable properties. In particular, we find that structure-based regularization often improves variant selection compared to unregularized approaches, and never hurts.
期刊介绍:
Algorithms for Molecular Biology publishes articles on novel algorithms for biological sequence and structure analysis, phylogeny reconstruction, and combinatorial algorithms and machine learning.
Areas of interest include but are not limited to: algorithms for RNA and protein structure analysis, gene prediction and genome analysis, comparative sequence analysis and alignment, phylogeny, gene expression, machine learning, and combinatorial algorithms.
Where appropriate, manuscripts should describe applications to real-world data. However, pure algorithm papers are also welcome if future applications to biological data are to be expected, or if they address complexity or approximation issues of novel computational problems in molecular biology. Articles about novel software tools will be considered for publication if they contain some algorithmically interesting aspects.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


