{"title":"Mining Proteome Research Reports: A Bird's Eye View.","authors":"Jagajjit Sahu","doi":"10.3390/proteomes9020029","DOIUrl":null,"url":null,"abstract":"<p><p>The complexity of data has burgeoned to such an extent that scientists of every realm are encountering the incessant challenge of data management. Modern-day analytical approaches with the help of free source tools and programming languages have facilitated access to the context of the various domains as well as specific works reported. Here, with this article, an attempt has been made to provide a systematic analysis of all the available reports at PubMed on Proteome using text mining. The work is comprised of scientometrics as well as information extraction to provide the publication trends as well as frequent keywords, bioconcepts and most importantly gene-gene co-occurrence network. Out of 33,028 PMIDs collected initially, the segregation of 24,350 articles under 28 Medical Subject Headings (MeSH) was analyzed and plotted. Keyword link network and density visualizations were provided for the top 1000 frequent Mesh keywords. PubTator was used, and 322,026 bioconcepts were able to extracted under 10 classes (such as Gene, Disease, CellLine, etc.). Co-occurrence networks were constructed for PMID-bioconcept as well as bioconcept-bioconcept associations. Further, for creation of subnetwork with respect to gene-gene co-occurrence, a total of 11,100 unique genes participated with mTOR and AKT showing the highest (64) number of connections. The gene p53 was the most popular one in the network in accordance with both the degree and weighted degree centrality, which were 425 and 1414, respectively. The present piece of study is an amalgam of bibliometrics and scientific data mining methods looking deeper into the whole scale analysis of available literature on proteome.</p>","PeriodicalId":20877,"journal":{"name":"Proteomes","volume":"9 2","pages":""},"PeriodicalIF":4.0000,"publicationDate":"2021-06-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.3390/proteomes9020029","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Proteomes","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/proteomes9020029","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 1
Abstract
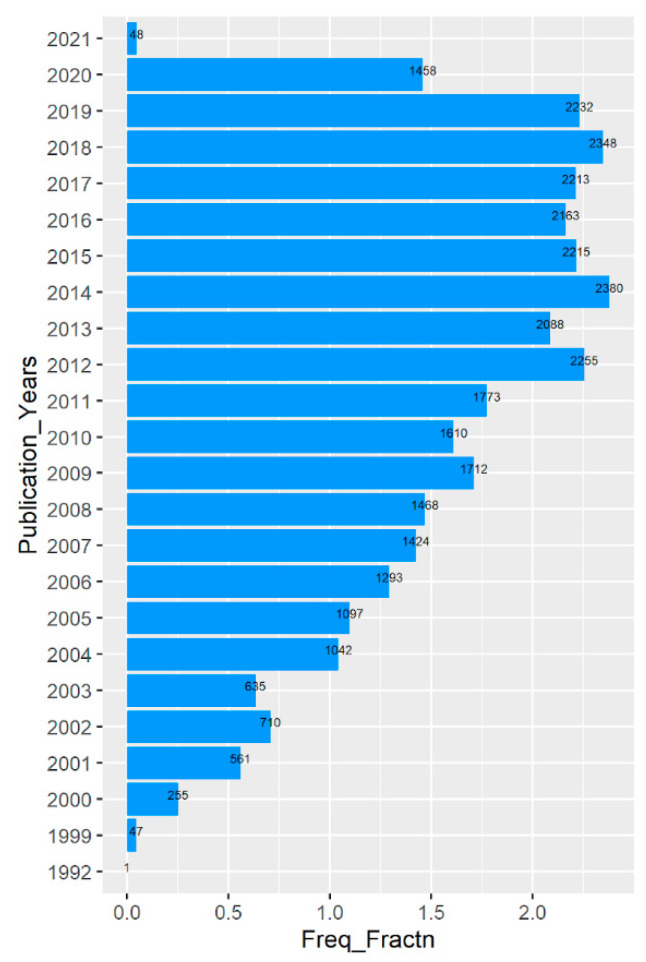
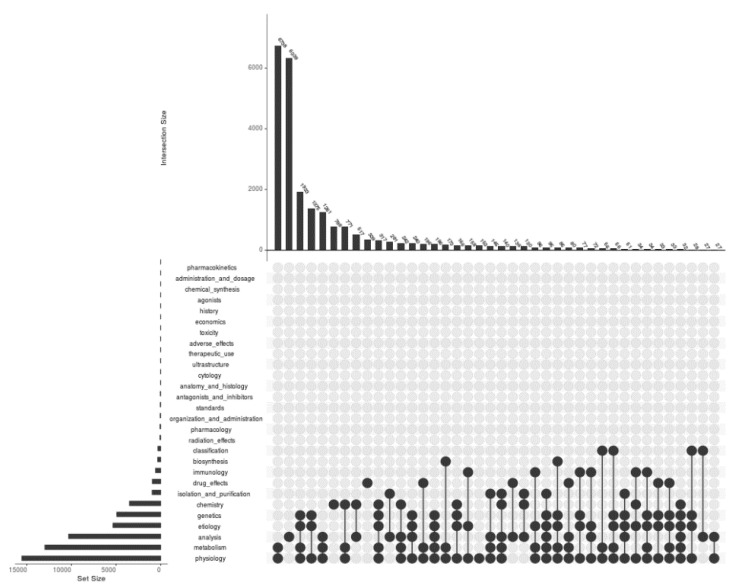
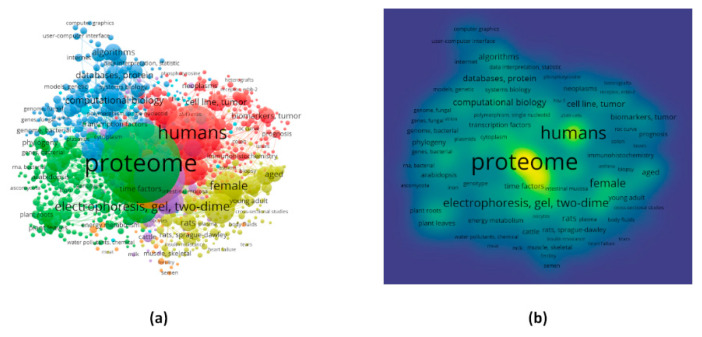
The complexity of data has burgeoned to such an extent that scientists of every realm are encountering the incessant challenge of data management. Modern-day analytical approaches with the help of free source tools and programming languages have facilitated access to the context of the various domains as well as specific works reported. Here, with this article, an attempt has been made to provide a systematic analysis of all the available reports at PubMed on Proteome using text mining. The work is comprised of scientometrics as well as information extraction to provide the publication trends as well as frequent keywords, bioconcepts and most importantly gene-gene co-occurrence network. Out of 33,028 PMIDs collected initially, the segregation of 24,350 articles under 28 Medical Subject Headings (MeSH) was analyzed and plotted. Keyword link network and density visualizations were provided for the top 1000 frequent Mesh keywords. PubTator was used, and 322,026 bioconcepts were able to extracted under 10 classes (such as Gene, Disease, CellLine, etc.). Co-occurrence networks were constructed for PMID-bioconcept as well as bioconcept-bioconcept associations. Further, for creation of subnetwork with respect to gene-gene co-occurrence, a total of 11,100 unique genes participated with mTOR and AKT showing the highest (64) number of connections. The gene p53 was the most popular one in the network in accordance with both the degree and weighted degree centrality, which were 425 and 1414, respectively. The present piece of study is an amalgam of bibliometrics and scientific data mining methods looking deeper into the whole scale analysis of available literature on proteome.
ProteomesBiochemistry, Genetics and Molecular Biology-Clinical Biochemistry
CiteScore
6.50
自引率
3.00%
发文量
37
审稿时长
11 weeks
期刊介绍:
Proteomes (ISSN 2227-7382) is an open access, peer reviewed journal on all aspects of proteome science. Proteomes covers the multi-disciplinary topics of structural and functional biology, protein chemistry, cell biology, methodology used for protein analysis, including mass spectrometry, protein arrays, bioinformatics, HTS assays, etc. Our aim is to encourage scientists to publish their experimental and theoretical results in as much detail as possible. Therefore, there is no restriction on the length of papers. Scope: -whole proteome analysis of any organism -disease/pharmaceutical studies -comparative proteomics -protein-ligand/protein interactions -structure/functional proteomics -gene expression -methodology -bioinformatics -applications of proteomics

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


