Vincent Lostanlen, Christian El-Hajj, Mathias Rossignol, Grégoire Lafay, Joakim Andén, Mathieu Lagrange
{"title":"Time-frequency scattering accurately models auditory similarities between instrumental playing techniques.","authors":"Vincent Lostanlen, Christian El-Hajj, Mathias Rossignol, Grégoire Lafay, Joakim Andén, Mathieu Lagrange","doi":"10.1186/s13636-020-00187-z","DOIUrl":null,"url":null,"abstract":"<p><p>Instrumentalplaying techniques such as vibratos, glissandos, and trills often denote musical expressivity, both in classical and folk contexts. However, most existing approaches to music similarity retrieval fail to describe timbre beyond the so-called \"ordinary\" technique, use instrument identity as a proxy for timbre quality, and do not allow for customization to the perceptual idiosyncrasies of a new subject. In this article, we ask 31 human participants to organize 78 isolated notes into a set of timbre clusters. Analyzing their responses suggests that timbre perception operates within a more flexible taxonomy than those provided by instruments or playing techniques alone. In addition, we propose a machine listening model to recover the cluster graph of auditory similarities across instruments, mutes, and techniques. Our model relies on joint time-frequency scattering features to extract spectrotemporal modulations as acoustic features. Furthermore, it minimizes triplet loss in the cluster graph by means of the large-margin nearest neighbor (LMNN) metric learning algorithm. Over a dataset of 9346 isolated notes, we report a state-of-the-art average precision at rank five (AP@5) of 99<i>.</i>0<i>%</i>±1. An ablation study demonstrates that removing either the joint time-frequency scattering transform or the metric learning algorithm noticeably degrades performance.</p>","PeriodicalId":49202,"journal":{"name":"Eurasip Journal on Audio Speech and Music Processing","volume":"2021 1","pages":"3"},"PeriodicalIF":1.9000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13636-020-00187-z","citationCount":"10","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Audio Speech and Music Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13636-020-00187-z","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/1/11 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 10
Abstract
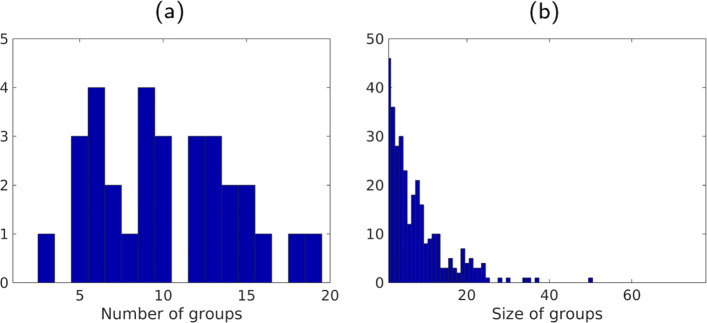
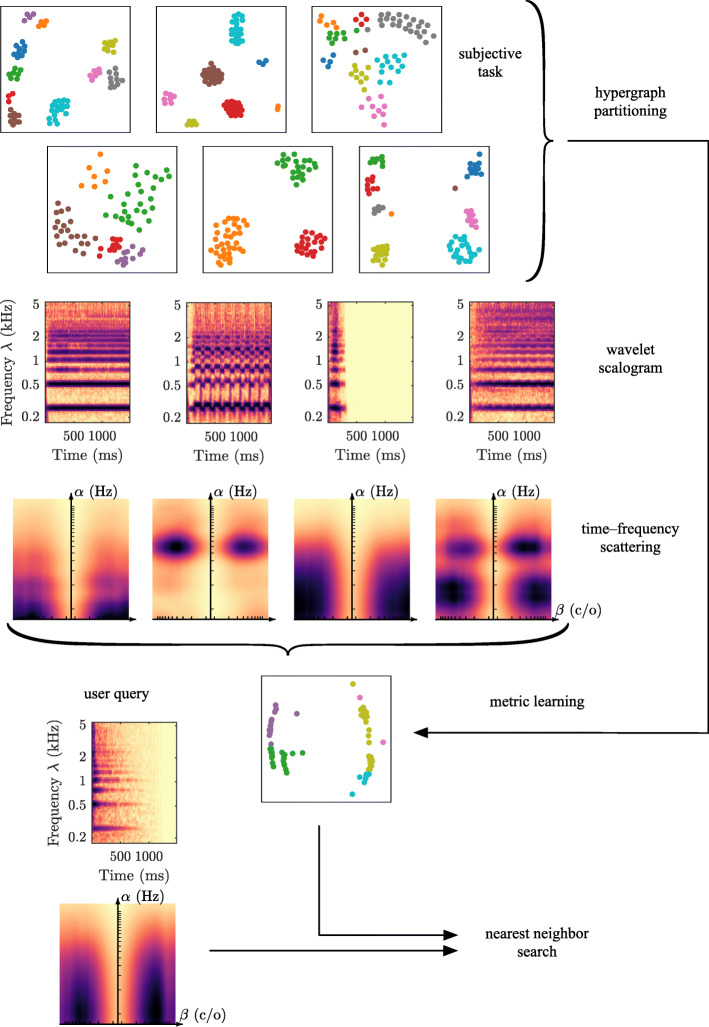
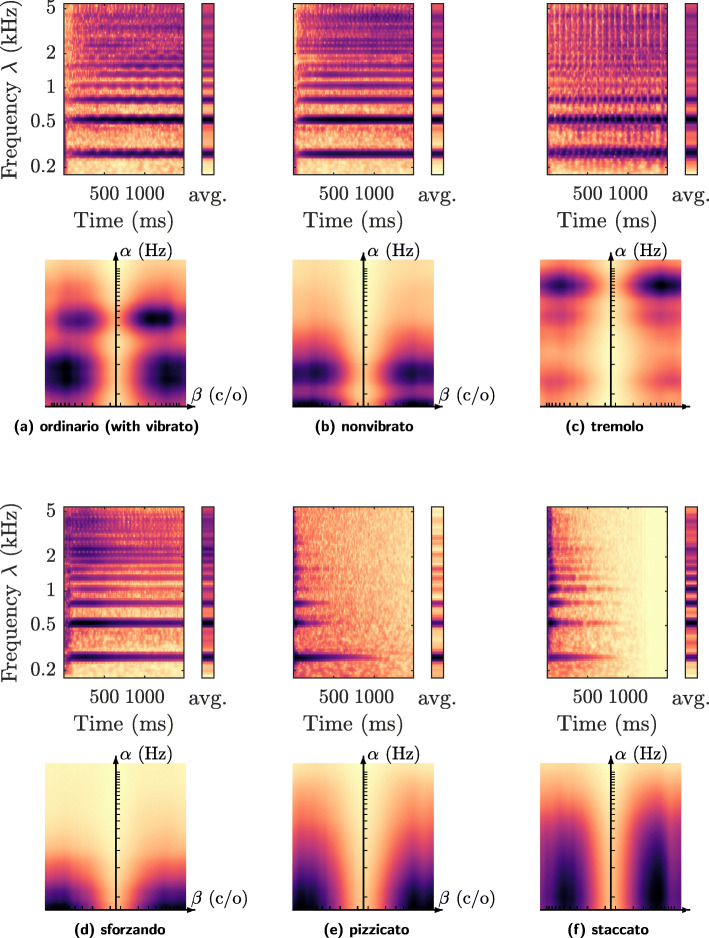
Instrumentalplaying techniques such as vibratos, glissandos, and trills often denote musical expressivity, both in classical and folk contexts. However, most existing approaches to music similarity retrieval fail to describe timbre beyond the so-called "ordinary" technique, use instrument identity as a proxy for timbre quality, and do not allow for customization to the perceptual idiosyncrasies of a new subject. In this article, we ask 31 human participants to organize 78 isolated notes into a set of timbre clusters. Analyzing their responses suggests that timbre perception operates within a more flexible taxonomy than those provided by instruments or playing techniques alone. In addition, we propose a machine listening model to recover the cluster graph of auditory similarities across instruments, mutes, and techniques. Our model relies on joint time-frequency scattering features to extract spectrotemporal modulations as acoustic features. Furthermore, it minimizes triplet loss in the cluster graph by means of the large-margin nearest neighbor (LMNN) metric learning algorithm. Over a dataset of 9346 isolated notes, we report a state-of-the-art average precision at rank five (AP@5) of 99.0%±1. An ablation study demonstrates that removing either the joint time-frequency scattering transform or the metric learning algorithm noticeably degrades performance.
期刊介绍:
The aim of “EURASIP Journal on Audio, Speech, and Music Processing” is to bring together researchers, scientists and engineers working on the theory and applications of the processing of various audio signals, with a specific focus on speech and music. EURASIP Journal on Audio, Speech, and Music Processing will be an interdisciplinary journal for the dissemination of all basic and applied aspects of speech communication and audio processes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


