Phyllis M Thangaraj, Benjamin R Kummer, Tal Lorberbaum, Mitchell S V Elkind, Nicholas P Tatonetti
{"title":"Comparative analysis, applications, and interpretation of electronic health record-based stroke phenotyping methods.","authors":"Phyllis M Thangaraj, Benjamin R Kummer, Tal Lorberbaum, Mitchell S V Elkind, Nicholas P Tatonetti","doi":"10.1186/s13040-020-00230-x","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Accurate identification of acute ischemic stroke (AIS) patient cohorts is essential for a wide range of clinical investigations. Automated phenotyping methods that leverage electronic health records (EHRs) represent a fundamentally new approach cohort identification without current laborious and ungeneralizable generation of phenotyping algorithms. We systematically compared and evaluated the ability of machine learning algorithms and case-control combinations to phenotype acute ischemic stroke patients using data from an EHR.</p><p><strong>Materials and methods: </strong>Using structured patient data from the EHR at a tertiary-care hospital system, we built and evaluated machine learning models to identify patients with AIS based on 75 different case-control and classifier combinations. We then estimated the prevalence of AIS patients across the EHR. Finally, we externally validated the ability of the models to detect AIS patients without AIS diagnosis codes using the UK Biobank.</p><p><strong>Results: </strong>Across all models, we found that the mean AUROC for detecting AIS was 0.963 ± 0.0520 and average precision score 0.790 ± 0.196 with minimal feature processing. Classifiers trained with cases with AIS diagnosis codes and controls with no cerebrovascular disease codes had the best average F1 score (0.832 ± 0.0383). In the external validation, we found that the top probabilities from a model-predicted AIS cohort were significantly enriched for AIS patients without AIS diagnosis codes (60-150 fold over expected).</p><p><strong>Conclusions: </strong>Our findings support machine learning algorithms as a generalizable way to accurately identify AIS patients without using process-intensive manual feature curation. When a set of AIS patients is unavailable, diagnosis codes may be used to train classifier models.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"13 1","pages":"21"},"PeriodicalIF":4.0000,"publicationDate":"2020-12-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7720570/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-020-00230-x","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Accurate identification of acute ischemic stroke (AIS) patient cohorts is essential for a wide range of clinical investigations. Automated phenotyping methods that leverage electronic health records (EHRs) represent a fundamentally new approach cohort identification without current laborious and ungeneralizable generation of phenotyping algorithms. We systematically compared and evaluated the ability of machine learning algorithms and case-control combinations to phenotype acute ischemic stroke patients using data from an EHR.
Materials and methods: Using structured patient data from the EHR at a tertiary-care hospital system, we built and evaluated machine learning models to identify patients with AIS based on 75 different case-control and classifier combinations. We then estimated the prevalence of AIS patients across the EHR. Finally, we externally validated the ability of the models to detect AIS patients without AIS diagnosis codes using the UK Biobank.
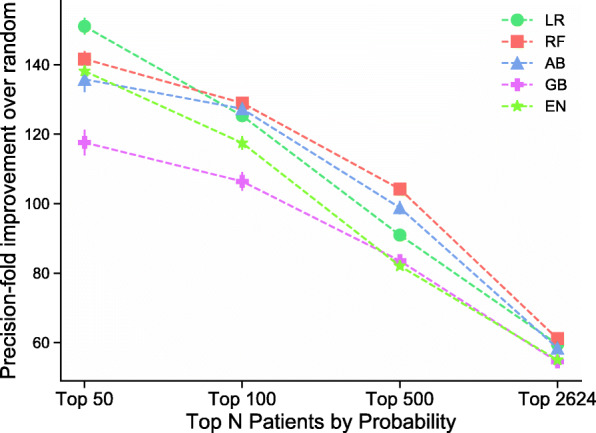
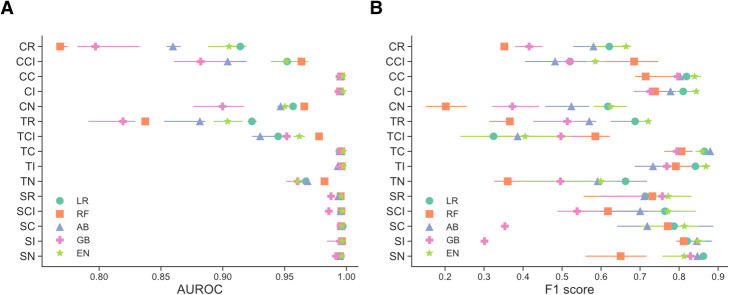
Results: Across all models, we found that the mean AUROC for detecting AIS was 0.963 ± 0.0520 and average precision score 0.790 ± 0.196 with minimal feature processing. Classifiers trained with cases with AIS diagnosis codes and controls with no cerebrovascular disease codes had the best average F1 score (0.832 ± 0.0383). In the external validation, we found that the top probabilities from a model-predicted AIS cohort were significantly enriched for AIS patients without AIS diagnosis codes (60-150 fold over expected).
Conclusions: Our findings support machine learning algorithms as a generalizable way to accurately identify AIS patients without using process-intensive manual feature curation. When a set of AIS patients is unavailable, diagnosis codes may be used to train classifier models.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


