Bethany M Moore, Peipei Wang, Pengxiang Fan, Aaron Lee, Bryan Leong, Yann-Ru Lou, Craig A Schenck, Koichi Sugimoto, Robert Last, Melissa D Lehti-Shiu, Cornelius S Barry, Shin-Han Shiu
{"title":"Within- and cross-species predictions of plant specialized metabolism genes using transfer learning.","authors":"Bethany M Moore, Peipei Wang, Pengxiang Fan, Aaron Lee, Bryan Leong, Yann-Ru Lou, Craig A Schenck, Koichi Sugimoto, Robert Last, Melissa D Lehti-Shiu, Cornelius S Barry, Shin-Han Shiu","doi":"10.1093/insilicoplants/diaa005","DOIUrl":null,"url":null,"abstract":"<p><p>Plant specialized metabolites mediate interactions between plants and the environment and have significant agronomical/pharmaceutical value. Most genes involved in specialized metabolism (SM) are unknown because of the large number of metabolites and the challenge in differentiating SM genes from general metabolism (GM) genes. Plant models like <i>Arabidopsis thaliana</i> have extensive, experimentally derived annotations, whereas many non-model species do not. Here we employed a machine learning strategy, transfer learning, where knowledge from <i>A. thaliana</i> is transferred to predict gene functions in cultivated tomato with fewer experimentally annotated genes. The first tomato SM/GM prediction model using only tomato data performs well (<i>F</i>-measure = 0.74, compared with 0.5 for random and 1.0 for perfect predictions), but from manually curating 88 SM/GM genes, we found many mis-predicted entries were likely mis-annotated. When the SM/GM prediction models built with <i>A. thaliana</i> data were used to filter out genes where the <i>A. thaliana-</i>based model predictions disagreed with tomato annotations, the new tomato model trained with filtered data improved significantly (<i>F</i>-measure = 0.92). Our study demonstrates that SM/GM genes can be better predicted by leveraging cross-species information. Additionally, our findings provide an example for transfer learning in genomics where knowledge can be transferred from an information-rich species to an information-poor one.</p>","PeriodicalId":36138,"journal":{"name":"in silico Plants","volume":"2 1","pages":"diaa005"},"PeriodicalIF":2.4000,"publicationDate":"2020-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1093/insilicoplants/diaa005","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"in silico Plants","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/insilicoplants/diaa005","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/7/30 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"AGRONOMY","Score":null,"Total":0}
引用次数: 0
Abstract
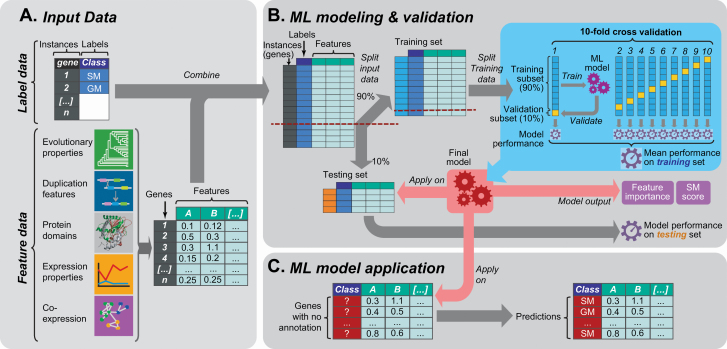
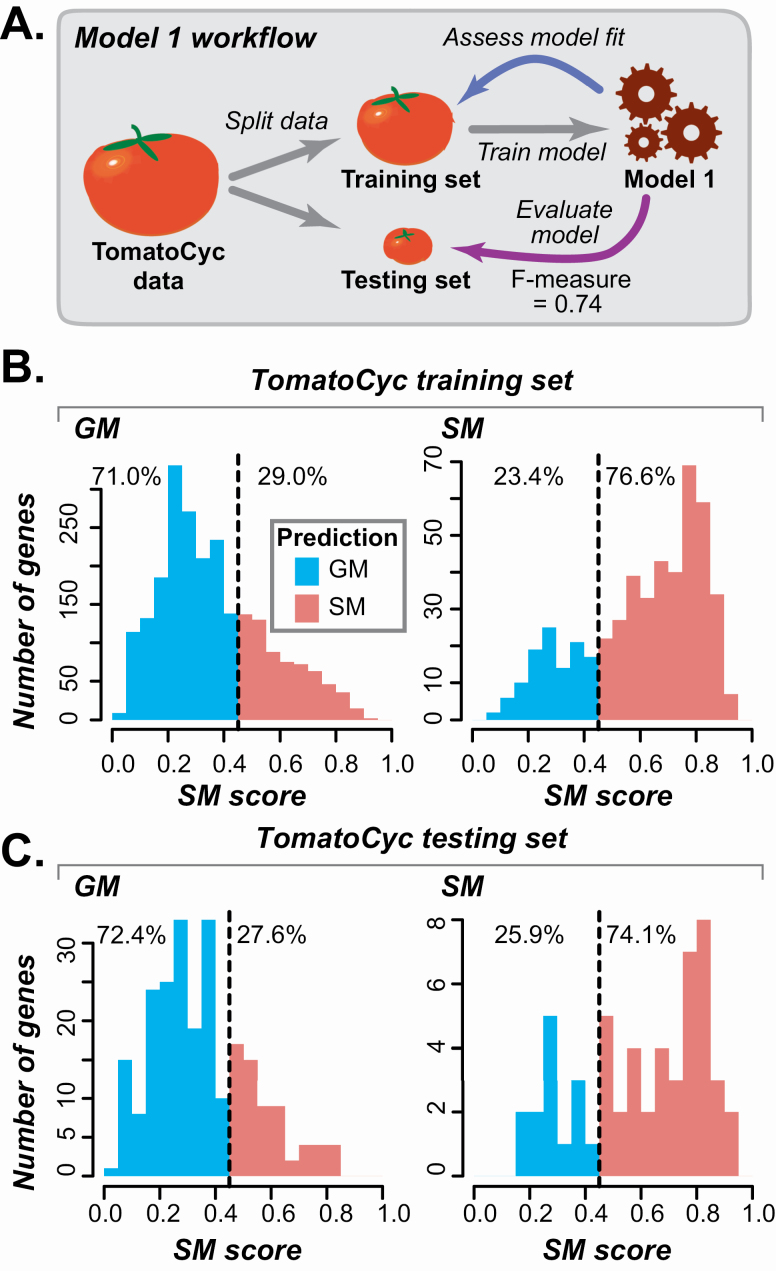
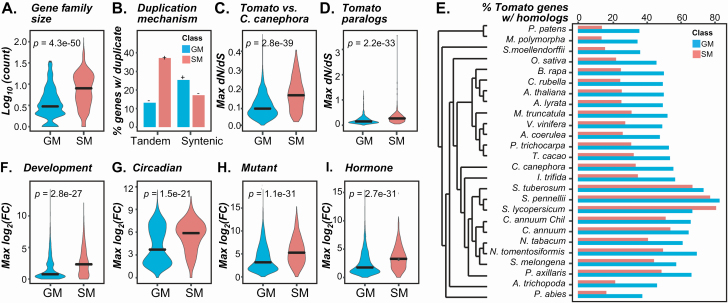
Plant specialized metabolites mediate interactions between plants and the environment and have significant agronomical/pharmaceutical value. Most genes involved in specialized metabolism (SM) are unknown because of the large number of metabolites and the challenge in differentiating SM genes from general metabolism (GM) genes. Plant models like Arabidopsis thaliana have extensive, experimentally derived annotations, whereas many non-model species do not. Here we employed a machine learning strategy, transfer learning, where knowledge from A. thaliana is transferred to predict gene functions in cultivated tomato with fewer experimentally annotated genes. The first tomato SM/GM prediction model using only tomato data performs well (F-measure = 0.74, compared with 0.5 for random and 1.0 for perfect predictions), but from manually curating 88 SM/GM genes, we found many mis-predicted entries were likely mis-annotated. When the SM/GM prediction models built with A. thaliana data were used to filter out genes where the A. thaliana-based model predictions disagreed with tomato annotations, the new tomato model trained with filtered data improved significantly (F-measure = 0.92). Our study demonstrates that SM/GM genes can be better predicted by leveraging cross-species information. Additionally, our findings provide an example for transfer learning in genomics where knowledge can be transferred from an information-rich species to an information-poor one.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


