{"title":"Algorithms for the quantitative Lock/Key model of cytoplasmic incompatibility.","authors":"Tiziana Calamoneri, Mattia Gastaldello, Arnaud Mary, Marie-France Sagot, Blerina Sinaimeri","doi":"10.1186/s13015-020-00174-1","DOIUrl":null,"url":null,"abstract":"<p><p>Cytoplasmic incompatibility (CI) relates to the manipulation by the parasite <i>Wolbachia</i> of its host reproduction. Despite its widespread occurrence, the molecular basis of CI remains unclear and theoretical models have been proposed to understand the phenomenon. We consider in this paper the quantitative Lock-Key model which currently represents a good hypothesis that is consistent with the data available. CI is in this case modelled as the problem of covering the edges of a bipartite graph with the minimum number of chain subgraphs. This problem is already known to be NP-hard, and we provide an exponential algorithm with a non trivial complexity. It is frequent that depending on the dataset, there may be many optimal solutions which can be biologically quite different among them. To rely on a single optimal solution may therefore be problematic. To this purpose, we address the problem of enumerating (listing) all minimal chain subgraph covers of a bipartite graph and show that it can be solved in quasi-polynomial time. Interestingly, in order to solve the above problems, we considered also the problem of enumerating all the maximal chain subgraphs of a bipartite graph and improved on the current results in the literature for the latter. Finally, to demonstrate the usefulness of our methods we show an application on a real dataset.</p>","PeriodicalId":50823,"journal":{"name":"Algorithms for Molecular Biology","volume":"15 ","pages":"14"},"PeriodicalIF":1.5000,"publicationDate":"2020-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13015-020-00174-1","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithms for Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-020-00174-1","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/1/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 1
Abstract
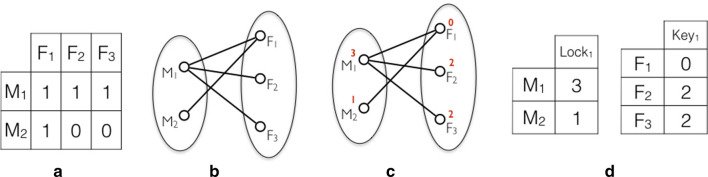
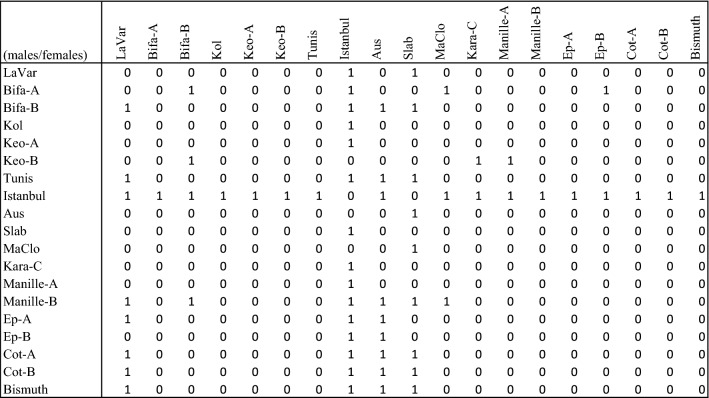
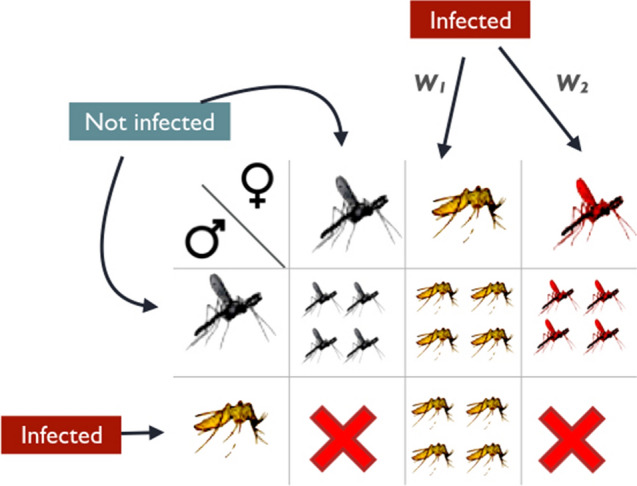
Cytoplasmic incompatibility (CI) relates to the manipulation by the parasite Wolbachia of its host reproduction. Despite its widespread occurrence, the molecular basis of CI remains unclear and theoretical models have been proposed to understand the phenomenon. We consider in this paper the quantitative Lock-Key model which currently represents a good hypothesis that is consistent with the data available. CI is in this case modelled as the problem of covering the edges of a bipartite graph with the minimum number of chain subgraphs. This problem is already known to be NP-hard, and we provide an exponential algorithm with a non trivial complexity. It is frequent that depending on the dataset, there may be many optimal solutions which can be biologically quite different among them. To rely on a single optimal solution may therefore be problematic. To this purpose, we address the problem of enumerating (listing) all minimal chain subgraph covers of a bipartite graph and show that it can be solved in quasi-polynomial time. Interestingly, in order to solve the above problems, we considered also the problem of enumerating all the maximal chain subgraphs of a bipartite graph and improved on the current results in the literature for the latter. Finally, to demonstrate the usefulness of our methods we show an application on a real dataset.
期刊介绍:
Algorithms for Molecular Biology publishes articles on novel algorithms for biological sequence and structure analysis, phylogeny reconstruction, and combinatorial algorithms and machine learning.
Areas of interest include but are not limited to: algorithms for RNA and protein structure analysis, gene prediction and genome analysis, comparative sequence analysis and alignment, phylogeny, gene expression, machine learning, and combinatorial algorithms.
Where appropriate, manuscripts should describe applications to real-world data. However, pure algorithm papers are also welcome if future applications to biological data are to be expected, or if they address complexity or approximation issues of novel computational problems in molecular biology. Articles about novel software tools will be considered for publication if they contain some algorithmically interesting aspects.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


