Gregory E Simon, Susan M Shortreed, R Yates Coley, Robert B Penfold, Rebecca C Rossom, Beth E Waitzfelder, Katherine Sanchez, Frances L Lynch
{"title":"Assessing and Minimizing Re-identification Risk in Research Data Derived from Health Care Records.","authors":"Gregory E Simon, Susan M Shortreed, R Yates Coley, Robert B Penfold, Rebecca C Rossom, Beth E Waitzfelder, Katherine Sanchez, Frances L Lynch","doi":"10.5334/egems.270","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Sharing of research data derived from health system records supports the rigor and reproducibility of primary research and can accelerate research progress through secondary use. But public sharing of such data can create risk of re-identifying individuals, exposing sensitive health information.</p><p><strong>Method: </strong>We describe a framework for assessing re-identification risk that includes: identifying data elements in a research dataset that overlap with external data sources, identifying small classes of records defined by unique combinations of those data elements, and considering the pattern of population overlap between the research dataset and an external source. We also describe alternative strategies for mitigating risk when the external data source can or cannot be directly examined.</p><p><strong>Results: </strong>We illustrate this framework using the example of a large database used to develop and validate models predicting suicidal behavior after an outpatient visit. We identify elements in the research dataset that might create risk and propose a specific risk mitigation strategy: deleting indicators for health system (a proxy for state of residence) and visit year.</p><p><strong>Discussion: </strong>Researchers holding health system data must balance the public health value of data sharing against the duty to protect the privacy of health system members. Specific steps can provide a useful estimate of re-identification risk and point to effective risk mitigation strategies.</p>","PeriodicalId":72880,"journal":{"name":"EGEMS (Washington, DC)","volume":"7 1","pages":"6"},"PeriodicalIF":0.0000,"publicationDate":"2019-03-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6450246/pdf/","citationCount":"26","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EGEMS (Washington, DC)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5334/egems.270","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 26
Abstract
Background: Sharing of research data derived from health system records supports the rigor and reproducibility of primary research and can accelerate research progress through secondary use. But public sharing of such data can create risk of re-identifying individuals, exposing sensitive health information.
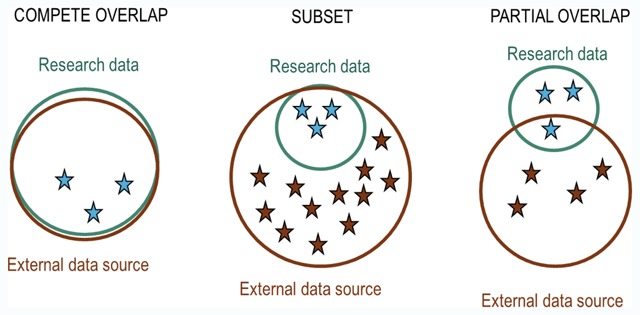
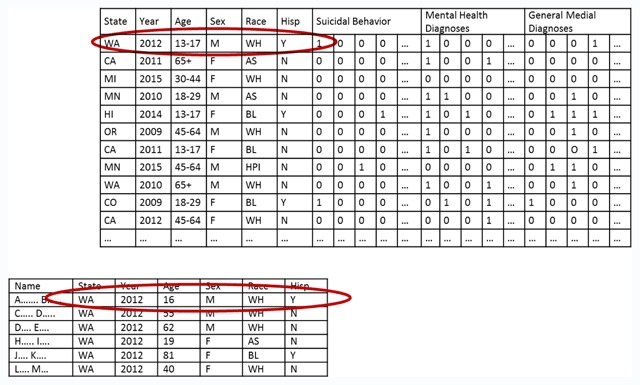
Method: We describe a framework for assessing re-identification risk that includes: identifying data elements in a research dataset that overlap with external data sources, identifying small classes of records defined by unique combinations of those data elements, and considering the pattern of population overlap between the research dataset and an external source. We also describe alternative strategies for mitigating risk when the external data source can or cannot be directly examined.
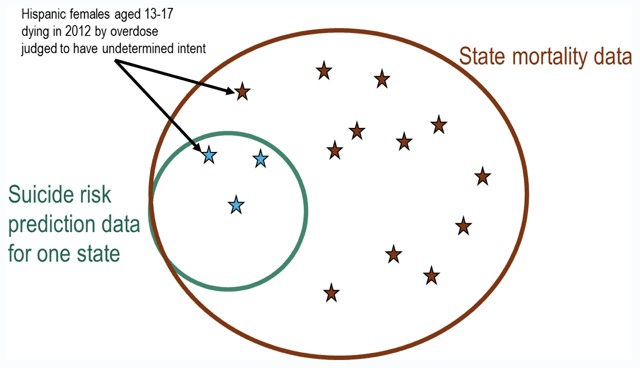
Results: We illustrate this framework using the example of a large database used to develop and validate models predicting suicidal behavior after an outpatient visit. We identify elements in the research dataset that might create risk and propose a specific risk mitigation strategy: deleting indicators for health system (a proxy for state of residence) and visit year.
Discussion: Researchers holding health system data must balance the public health value of data sharing against the duty to protect the privacy of health system members. Specific steps can provide a useful estimate of re-identification risk and point to effective risk mitigation strategies.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


