Terrence E Murphy, Sui W Tsang, Linda S Leo-Summers, Mary Geda, Dae H Kim, Esther Oh, Heather G Allore, John Dodson, Alexandra M Hajduk, Thomas M Gill, Sarwat I Chaudhry
{"title":"Bayesian Model Averaging for Selection of a Risk Prediction Model for Death within Thirty Days of Discharge: The SILVER-AMI Study.","authors":"Terrence E Murphy, Sui W Tsang, Linda S Leo-Summers, Mary Geda, Dae H Kim, Esther Oh, Heather G Allore, John Dodson, Alexandra M Hajduk, Thomas M Gill, Sarwat I Chaudhry","doi":"10.6000/1929-6029.2019.08.01","DOIUrl":null,"url":null,"abstract":"<p><p>We describe a selection process for a multivariable risk prediction model of death within 30 days of hospital discharge in the SILVER-AMI study. This large, multi-site observational study included observational data from 2000 persons 75 years and older hospitalized for acute myocardial infarction (AMI) from 94 community and academic hospitals across the United States and featured a large number of candidate variables from demographic, cardiac, and geriatric domains, whose missing values were multiply imputed prior to model selection. Our objective was to demonstrate that Bayesian Model Averaging (BMA) represents a viable model selection approach in this context. BMA was compared to three other backward-selection approaches: Akaike information criterion, Bayesian information criterion, and traditional p-value. Traditional backward-selection was used to choose 20 candidate variables from the initial, larger pool of five imputations. Models were subsequently chosen from those candidates using the four approaches on each of 10 imputations. With average posterior effect probability ≥ 50% as the selection criterion, BMA chose the most parsimonious model with four variables, with average C statistic of 78%, good calibration, optimism of 1.3%, and heuristic shrinkage of 0.93. These findings illustrate the utility and flexibility of using BMA for selecting a multivariable risk prediction model from many candidates over multiply imputed datasets.</p>","PeriodicalId":73480,"journal":{"name":"International journal of statistics in medical research","volume":"8 ","pages":"1-7"},"PeriodicalIF":0.0000,"publicationDate":"2019-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/3d/86/nihms-1027580.PMC6553647.pdf","citationCount":"9","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of statistics in medical research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.6000/1929-6029.2019.08.01","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2019/4/5 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 9
Abstract
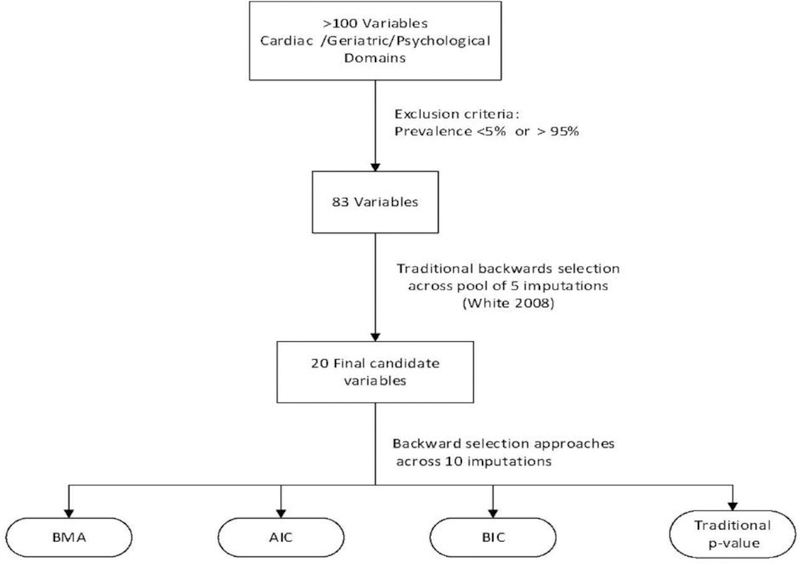
We describe a selection process for a multivariable risk prediction model of death within 30 days of hospital discharge in the SILVER-AMI study. This large, multi-site observational study included observational data from 2000 persons 75 years and older hospitalized for acute myocardial infarction (AMI) from 94 community and academic hospitals across the United States and featured a large number of candidate variables from demographic, cardiac, and geriatric domains, whose missing values were multiply imputed prior to model selection. Our objective was to demonstrate that Bayesian Model Averaging (BMA) represents a viable model selection approach in this context. BMA was compared to three other backward-selection approaches: Akaike information criterion, Bayesian information criterion, and traditional p-value. Traditional backward-selection was used to choose 20 candidate variables from the initial, larger pool of five imputations. Models were subsequently chosen from those candidates using the four approaches on each of 10 imputations. With average posterior effect probability ≥ 50% as the selection criterion, BMA chose the most parsimonious model with four variables, with average C statistic of 78%, good calibration, optimism of 1.3%, and heuristic shrinkage of 0.93. These findings illustrate the utility and flexibility of using BMA for selecting a multivariable risk prediction model from many candidates over multiply imputed datasets.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


