Lavinia Egidi, Felipe A Louza, Giovanni Manzini, Guilherme P Telles
{"title":"External memory BWT and LCP computation for sequence collections with applications.","authors":"Lavinia Egidi, Felipe A Louza, Giovanni Manzini, Guilherme P Telles","doi":"10.1186/s13015-019-0140-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Sequencing technologies produce larger and larger collections of biosequences that have to be stored in compressed indices supporting fast search operations. Many compressed indices are based on the Burrows-Wheeler Transform (BWT) and the longest common prefix (LCP) array. Because of the sheer size of the input it is important to build these data structures in external memory and time using in the best possible way the available RAM.</p><p><strong>Results: </strong>We propose a space-efficient algorithm to compute the BWT and LCP array for a collection of sequences in the external or semi-external memory setting. Our algorithm splits the input collection into subcollections sufficiently small that it can compute their BWT in RAM using an optimal linear time algorithm. Next, it merges the partial BWTs in external or semi-external memory and in the process it also computes the LCP values. Our algorithm can be modified to output two additional arrays that, combined with the BWT and LCP array, provide simple, scan-based, external memory algorithms for three well known problems in bioinformatics: the computation of maximal repeats, the all pairs suffix-prefix overlaps, and the construction of succinct de Bruijn graphs.</p><p><strong>Conclusions: </strong>We prove that our algorithm performs <math><mrow><mi>O</mi> <mo>(</mo> <mi>n</mi> <mspace></mspace> <mi>maxlcp</mi> <mo>)</mo></mrow> </math> sequential I/Os, where <i>n</i> is the total length of the collection and <math><mi>maxlcp</mi></math> is the maximum LCP value. The experimental results show that our algorithm is only slightly slower than the state of the art for short sequences but it is up to 40 times faster for longer sequences or when the available RAM is at least equal to the size of the input.</p>","PeriodicalId":50823,"journal":{"name":"Algorithms for Molecular Biology","volume":" ","pages":"6"},"PeriodicalIF":1.5000,"publicationDate":"2019-03-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13015-019-0140-0","citationCount":"30","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithms for Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-019-0140-0","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2019/1/1 0:00:00","PubModel":"eCollection","JCR":"Q4","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 30
Abstract
Background: Sequencing technologies produce larger and larger collections of biosequences that have to be stored in compressed indices supporting fast search operations. Many compressed indices are based on the Burrows-Wheeler Transform (BWT) and the longest common prefix (LCP) array. Because of the sheer size of the input it is important to build these data structures in external memory and time using in the best possible way the available RAM.
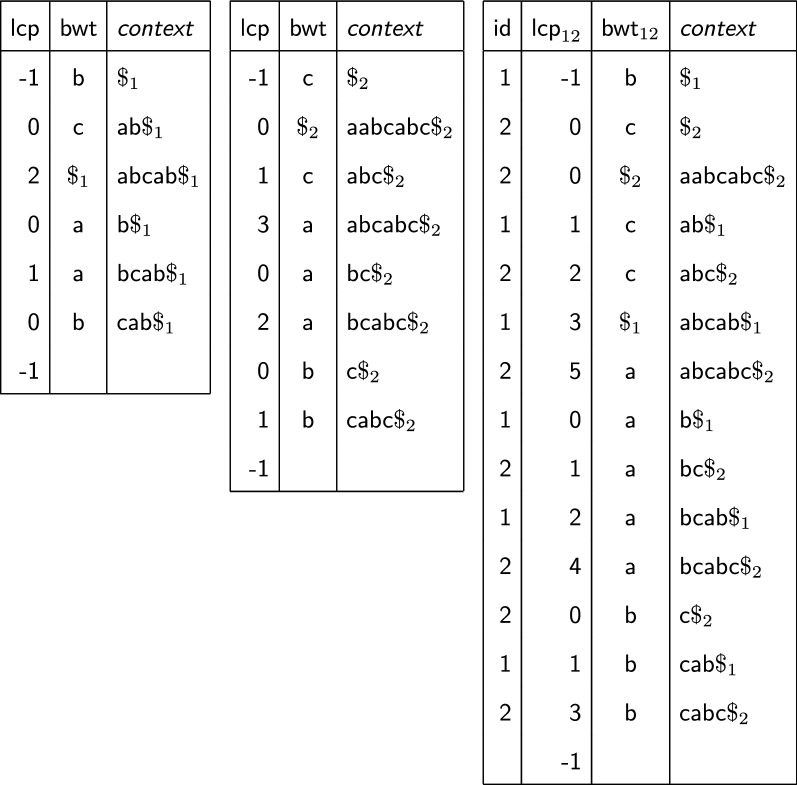
Results: We propose a space-efficient algorithm to compute the BWT and LCP array for a collection of sequences in the external or semi-external memory setting. Our algorithm splits the input collection into subcollections sufficiently small that it can compute their BWT in RAM using an optimal linear time algorithm. Next, it merges the partial BWTs in external or semi-external memory and in the process it also computes the LCP values. Our algorithm can be modified to output two additional arrays that, combined with the BWT and LCP array, provide simple, scan-based, external memory algorithms for three well known problems in bioinformatics: the computation of maximal repeats, the all pairs suffix-prefix overlaps, and the construction of succinct de Bruijn graphs.
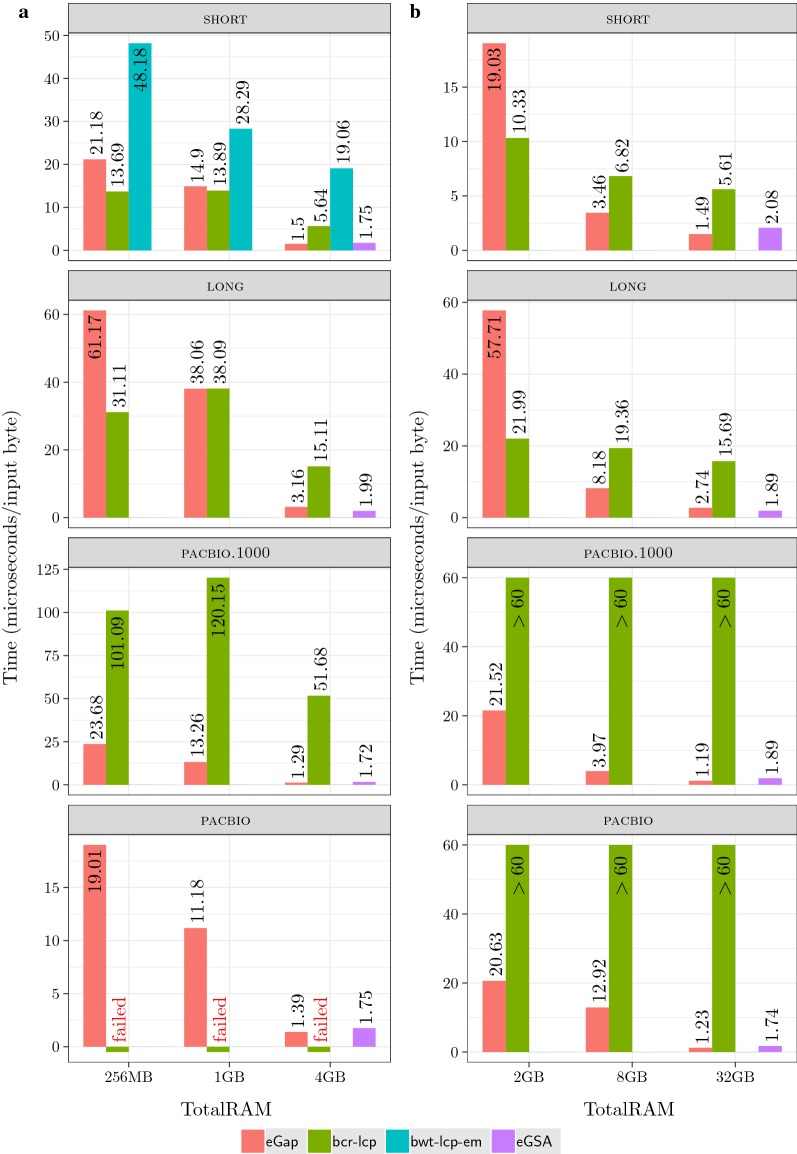
Conclusions: We prove that our algorithm performs sequential I/Os, where n is the total length of the collection and is the maximum LCP value. The experimental results show that our algorithm is only slightly slower than the state of the art for short sequences but it is up to 40 times faster for longer sequences or when the available RAM is at least equal to the size of the input.
期刊介绍:
Algorithms for Molecular Biology publishes articles on novel algorithms for biological sequence and structure analysis, phylogeny reconstruction, and combinatorial algorithms and machine learning.
Areas of interest include but are not limited to: algorithms for RNA and protein structure analysis, gene prediction and genome analysis, comparative sequence analysis and alignment, phylogeny, gene expression, machine learning, and combinatorial algorithms.
Where appropriate, manuscripts should describe applications to real-world data. However, pure algorithm papers are also welcome if future applications to biological data are to be expected, or if they address complexity or approximation issues of novel computational problems in molecular biology. Articles about novel software tools will be considered for publication if they contain some algorithmically interesting aspects.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


