Gavin Welch, Friedrich von Recklinghausen, Andreas Taenzer, Lucy Savitz, Lisa Weiss
{"title":"Data Cleaning in the Evaluation of a Multi-Site Intervention Project.","authors":"Gavin Welch, Friedrich von Recklinghausen, Andreas Taenzer, Lucy Savitz, Lisa Weiss","doi":"10.5334/egems.196","DOIUrl":null,"url":null,"abstract":"<p><strong>Context: </strong>The High Value Healthcare Collaborative (HVHC) sepsis project was a two-year multi-site project where Member health care delivery systems worked on improving sepsis care using a dissemination & implementation framework designed by HVHC. As part of the project evaluation, participating Members provided 5 data submissions over the project period. Members created data files using a uniform specification, but the data sources and methods used to create the data sets differed. Extensive data cleaning was necessary to get a data set usable for the evaluation analysis.</p><p><strong>Case description: </strong>HVHC was the coordinating center for the project and received and cleaned all data submissions. Submissions received 3 sequentially more detailed levels of checking by HVHC. The most detailed level evaluated validity by comparing values within-Member over time and between Member. For a subset of episodes Member-submitted data were compared to matched Medicare claims data.</p><p><strong>Findings: </strong>Inconsistencies in data submissions, particularly for length-of-stay variables were common in early submissions and decreased with subsequent submissions. Multiple resubmissions were sometimes required to get clean data. Data checking also uncovered a systematic difference in the way Medicare and some members defined intensive care unit stay.</p><p><strong>Conclusions: </strong>Data checking is a critical for ensuring valid analytic results for projects using electronic health record data. It is important to budget sufficient resources for data checking. Interim data submissions and checks help find anomalies early. Data resubmissions should be checked as fixes can introduce new errors. Communicating with those responsible for creating the data set provides critical information.</p>","PeriodicalId":72880,"journal":{"name":"EGEMS (Washington, DC)","volume":"5 3","pages":"4"},"PeriodicalIF":0.0000,"publicationDate":"2017-12-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5983076/pdf/","citationCount":"10","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EGEMS (Washington, DC)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5334/egems.196","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 10
Abstract
Context: The High Value Healthcare Collaborative (HVHC) sepsis project was a two-year multi-site project where Member health care delivery systems worked on improving sepsis care using a dissemination & implementation framework designed by HVHC. As part of the project evaluation, participating Members provided 5 data submissions over the project period. Members created data files using a uniform specification, but the data sources and methods used to create the data sets differed. Extensive data cleaning was necessary to get a data set usable for the evaluation analysis.
Case description: HVHC was the coordinating center for the project and received and cleaned all data submissions. Submissions received 3 sequentially more detailed levels of checking by HVHC. The most detailed level evaluated validity by comparing values within-Member over time and between Member. For a subset of episodes Member-submitted data were compared to matched Medicare claims data.
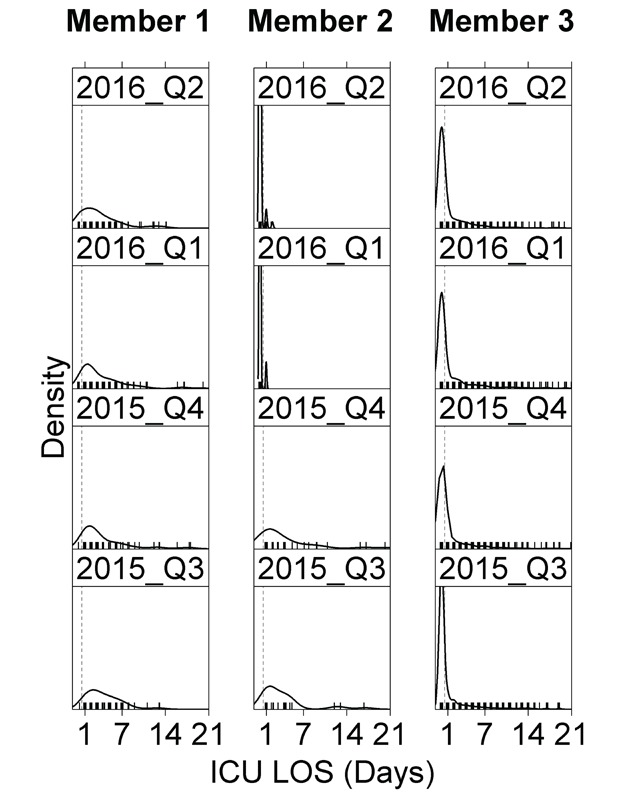
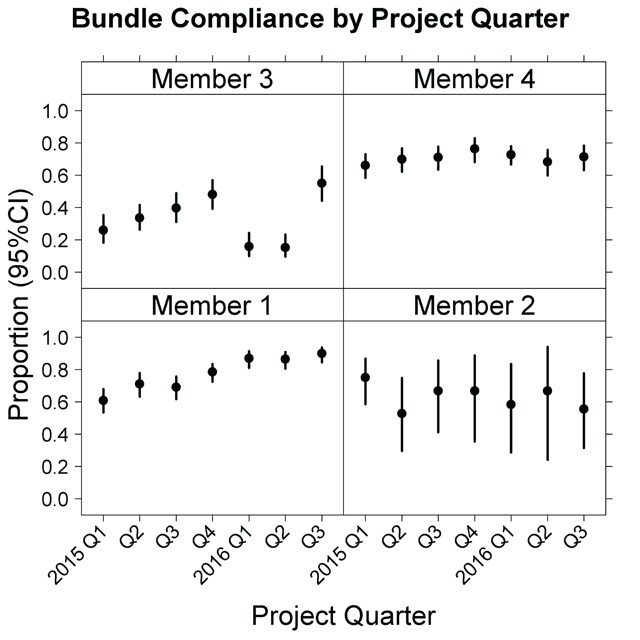
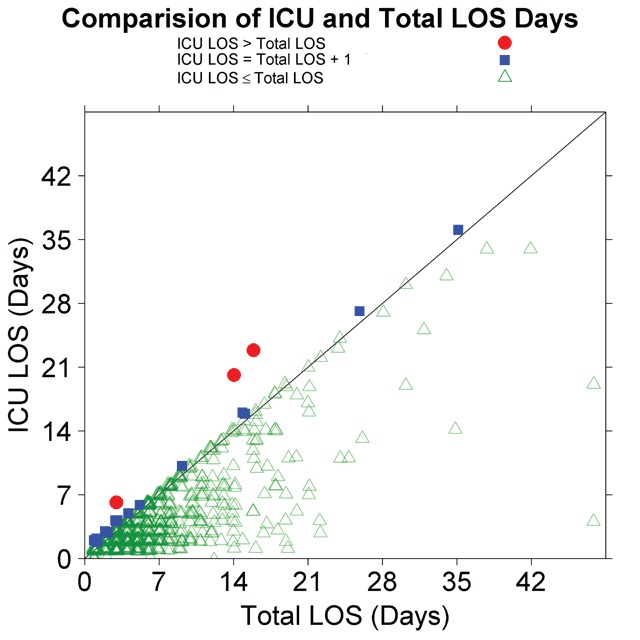
Findings: Inconsistencies in data submissions, particularly for length-of-stay variables were common in early submissions and decreased with subsequent submissions. Multiple resubmissions were sometimes required to get clean data. Data checking also uncovered a systematic difference in the way Medicare and some members defined intensive care unit stay.
Conclusions: Data checking is a critical for ensuring valid analytic results for projects using electronic health record data. It is important to budget sufficient resources for data checking. Interim data submissions and checks help find anomalies early. Data resubmissions should be checked as fixes can introduce new errors. Communicating with those responsible for creating the data set provides critical information.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


