Vladimer B Kobayashi, Stefan T Mol, Hannah A Berkers, Gábor Kismihók, Deanne N Den Hartog
{"title":"Text Classification for Organizational Researchers: A Tutorial.","authors":"Vladimer B Kobayashi, Stefan T Mol, Hannah A Berkers, Gábor Kismihók, Deanne N Den Hartog","doi":"10.1177/1094428117719322","DOIUrl":null,"url":null,"abstract":"<p><p>Organizations are increasingly interested in classifying texts or parts thereof into categories, as this enables more effective use of their information. Manual procedures for text classification work well for up to a few hundred documents. However, when the number of documents is larger, manual procedures become laborious, time-consuming, and potentially unreliable. Techniques from text mining facilitate the automatic assignment of text strings to categories, making classification expedient, fast, and reliable, which creates potential for its application in organizational research. The purpose of this article is to familiarize organizational researchers with text mining techniques from machine learning and statistics. We describe the text classification process in several roughly sequential steps, namely training data preparation, preprocessing, transformation, application of classification techniques, and validation, and provide concrete recommendations at each step. To help researchers develop their own text classifiers, the R code associated with each step is presented in a tutorial. The tutorial draws from our own work on job vacancy mining. We end the article by discussing how researchers can validate a text classification model and the associated output.</p>","PeriodicalId":19689,"journal":{"name":"Organizational Research Methods","volume":"21 3","pages":"766-799"},"PeriodicalIF":8.9000,"publicationDate":"2018-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1177/1094428117719322","citationCount":"47","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Organizational Research Methods","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1177/1094428117719322","RegionNum":2,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/7/12 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"MANAGEMENT","Score":null,"Total":0}
引用次数: 47
Abstract
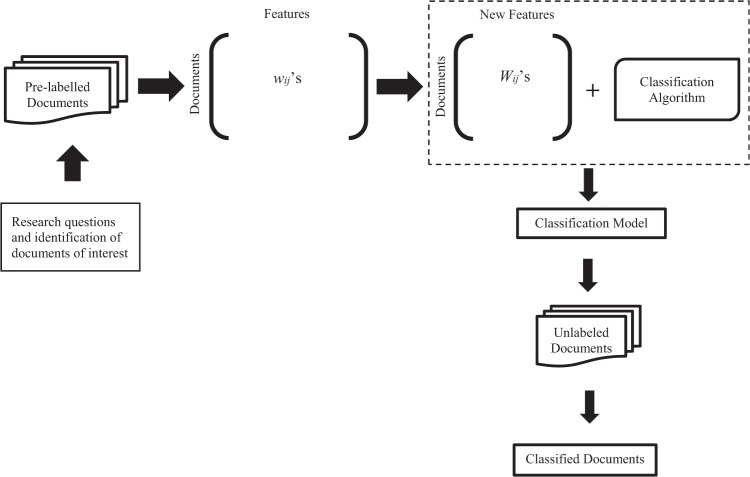
Organizations are increasingly interested in classifying texts or parts thereof into categories, as this enables more effective use of their information. Manual procedures for text classification work well for up to a few hundred documents. However, when the number of documents is larger, manual procedures become laborious, time-consuming, and potentially unreliable. Techniques from text mining facilitate the automatic assignment of text strings to categories, making classification expedient, fast, and reliable, which creates potential for its application in organizational research. The purpose of this article is to familiarize organizational researchers with text mining techniques from machine learning and statistics. We describe the text classification process in several roughly sequential steps, namely training data preparation, preprocessing, transformation, application of classification techniques, and validation, and provide concrete recommendations at each step. To help researchers develop their own text classifiers, the R code associated with each step is presented in a tutorial. The tutorial draws from our own work on job vacancy mining. We end the article by discussing how researchers can validate a text classification model and the associated output.
期刊介绍:
Organizational Research Methods (ORM) was founded with the aim of introducing pertinent methodological advancements to researchers in organizational sciences. The objective of ORM is to promote the application of current and emerging methodologies to advance both theory and research practices. Articles are expected to be comprehensible to readers with a background consistent with the methodological and statistical training provided in contemporary organizational sciences doctoral programs. The text should be presented in a manner that facilitates accessibility. For instance, highly technical content should be placed in appendices, and authors are encouraged to include example data and computer code when relevant. Additionally, authors should explicitly outline how their contribution has the potential to advance organizational theory and research practice.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


