{"title":"A hashtag recommendation system for twitter data streams.","authors":"Eriko Otsuka, Scott A Wallace, David Chiu","doi":"10.1186/s40649-016-0028-9","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Twitter has evolved into a powerful communication and information sharing tool used by millions of people around the world to post what is happening now. A hashtag, a keyword prefixed with a hash symbol (#), is a feature in Twitter to organize tweets and facilitate effective search among a massive volume of data. In this paper, we propose an automatic hashtag recommendation system that helps users find new hashtags related to their interests on-demand.</p><p><strong>Methods: </strong>For hashtag ranking, we propose the Hashtag Frequency-Inverse Hashtag Ubiquity (HF-IHU) ranking scheme, which is a variation of the well-known TF-IDF, that considers hashtag relevancy, as well as data sparseness which is one of the key challenges in analyzing microblog data. Our system is built on top of Hadoop, a leading platform for distributed computing, to provide scalable performance using Map-Reduce. Experiments on a large Twitter data set demonstrate that our method successfully yields relevant hashtags for user's interest and that recommendations are more stable and reliable than ranking tags based on tweet content similarity.</p><p><strong>Results and conclusions: </strong>Our results show that HF-IHU can achieve over 30 % hashtag recall when asked to identify the top 10 relevant hashtags for a particular tweet. Furthermore, our method out-performs kNN, k-popularity, and Naïve Bayes by 69, 54, and 17 %, respectively, on recall of the top 200 hashtags.</p>","PeriodicalId":52145,"journal":{"name":"Computational Social Networks","volume":"3 1","pages":"3"},"PeriodicalIF":0.0000,"publicationDate":"2016-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s40649-016-0028-9","citationCount":"25","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Social Networks","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s40649-016-0028-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2016/5/31 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Mathematics","Score":null,"Total":0}
引用次数: 25
Abstract
Background: Twitter has evolved into a powerful communication and information sharing tool used by millions of people around the world to post what is happening now. A hashtag, a keyword prefixed with a hash symbol (#), is a feature in Twitter to organize tweets and facilitate effective search among a massive volume of data. In this paper, we propose an automatic hashtag recommendation system that helps users find new hashtags related to their interests on-demand.
Methods: For hashtag ranking, we propose the Hashtag Frequency-Inverse Hashtag Ubiquity (HF-IHU) ranking scheme, which is a variation of the well-known TF-IDF, that considers hashtag relevancy, as well as data sparseness which is one of the key challenges in analyzing microblog data. Our system is built on top of Hadoop, a leading platform for distributed computing, to provide scalable performance using Map-Reduce. Experiments on a large Twitter data set demonstrate that our method successfully yields relevant hashtags for user's interest and that recommendations are more stable and reliable than ranking tags based on tweet content similarity.
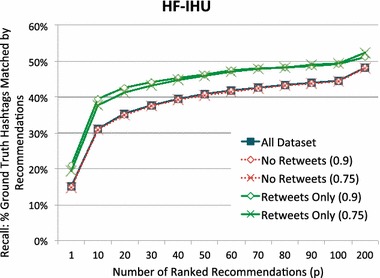
Results and conclusions: Our results show that HF-IHU can achieve over 30 % hashtag recall when asked to identify the top 10 relevant hashtags for a particular tweet. Furthermore, our method out-performs kNN, k-popularity, and Naïve Bayes by 69, 54, and 17 %, respectively, on recall of the top 200 hashtags.
期刊介绍:
Computational Social Networks showcases refereed papers dealing with all mathematical, computational and applied aspects of social computing. The objective of this journal is to advance and promote the theoretical foundation, mathematical aspects, and applications of social computing. Submissions are welcome which focus on common principles, algorithms and tools that govern network structures/topologies, network functionalities, security and privacy, network behaviors, information diffusions and influence, social recommendation systems which are applicable to all types of social networks and social media. Topics include (but are not limited to) the following: -Social network design and architecture -Mathematical modeling and analysis -Real-world complex networks -Information retrieval in social contexts, political analysts -Network structure analysis -Network dynamics optimization -Complex network robustness and vulnerability -Information diffusion models and analysis -Security and privacy -Searching in complex networks -Efficient algorithms -Network behaviors -Trust and reputation -Social Influence -Social Recommendation -Social media analysis -Big data analysis on online social networks This journal publishes rigorously refereed papers dealing with all mathematical, computational and applied aspects of social computing. The journal also includes reviews of appropriate books as special issues on hot topics.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


