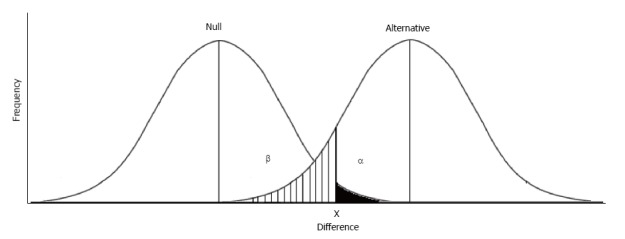
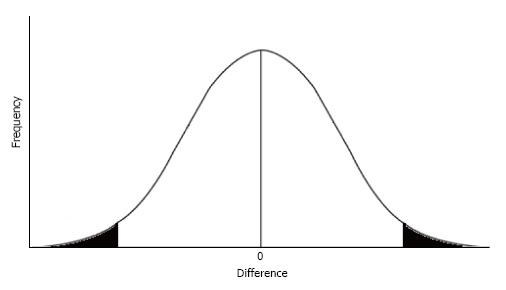
{"title":"Predictive power of statistical significance.","authors":"Thomas F Heston, Jackson M King","doi":"10.5662/wjm.v7.i4.112","DOIUrl":null,"url":null,"abstract":"<p><p>A statistically significant research finding should not be defined as a <i>P</i>-value of 0.05 or less, because this definition does not take into account study power. Statistical significance was originally defined by Fisher RA as a <i>P</i>-value of 0.05 or less. According to Fisher, any finding that is likely to occur by random variation no more than 1 in 20 times is considered significant. Neyman J and Pearson ES subsequently argued that Fisher's definition was incomplete. They proposed that statistical significance could only be determined by analyzing the chance of incorrectly considering a study finding was significant (a Type I error) or incorrectly considering a study finding was insignificant (a Type II error). Their definition of statistical significance is also incomplete because the error rates are considered separately, not together. A better definition of statistical significance is the positive predictive value of a <i>P</i>-value, which is equal to the power divided by the sum of power and the <i>P</i>-value. This definition is more complete and relevant than Fisher's or Neyman-Peason's definitions, because it takes into account both concepts of statistical significance. Using this definition, a statistically significant finding requires a <i>P</i>-value of 0.05 or less when the power is at least 95%, and a <i>P</i>-value of 0.032 or less when the power is 60%. To achieve statistical significance, <i>P</i>-values must be adjusted downward as the study power decreases.</p>","PeriodicalId":23729,"journal":{"name":"World journal of methodology","volume":"7 4","pages":"112-116"},"PeriodicalIF":0.0000,"publicationDate":"2017-12-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.5662/wjm.v7.i4.112","citationCount":"15","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"World journal of methodology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5662/wjm.v7.i4.112","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 15
Abstract
A statistically significant research finding should not be defined as a P-value of 0.05 or less, because this definition does not take into account study power. Statistical significance was originally defined by Fisher RA as a P-value of 0.05 or less. According to Fisher, any finding that is likely to occur by random variation no more than 1 in 20 times is considered significant. Neyman J and Pearson ES subsequently argued that Fisher's definition was incomplete. They proposed that statistical significance could only be determined by analyzing the chance of incorrectly considering a study finding was significant (a Type I error) or incorrectly considering a study finding was insignificant (a Type II error). Their definition of statistical significance is also incomplete because the error rates are considered separately, not together. A better definition of statistical significance is the positive predictive value of a P-value, which is equal to the power divided by the sum of power and the P-value. This definition is more complete and relevant than Fisher's or Neyman-Peason's definitions, because it takes into account both concepts of statistical significance. Using this definition, a statistically significant finding requires a P-value of 0.05 or less when the power is at least 95%, and a P-value of 0.032 or less when the power is 60%. To achieve statistical significance, P-values must be adjusted downward as the study power decreases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


