Thomas Desautels, Jacob Calvert, Jana Hoffman, Qingqing Mao, Melissa Jay, Grant Fletcher, Chris Barton, Uli Chettipally, Yaniv Kerem, Ritankar Das
{"title":"Using Transfer Learning for Improved Mortality Prediction in a Data-Scarce Hospital Setting.","authors":"Thomas Desautels, Jacob Calvert, Jana Hoffman, Qingqing Mao, Melissa Jay, Grant Fletcher, Chris Barton, Uli Chettipally, Yaniv Kerem, Ritankar Das","doi":"10.1177/1178222617712994","DOIUrl":null,"url":null,"abstract":"<p><p>Algorithm-based clinical decision support (CDS) systems associate patient-derived health data with outcomes of interest, such as in-hospital mortality. However, the quality of such associations often depends on the availability of site-specific training data. Without sufficient quantities of data, the underlying statistical apparatus cannot differentiate useful patterns from noise and, as a result, may underperform. This initial training data burden limits the widespread, out-of-the-box, use of machine learning-based risk scoring systems. In this study, we implement a statistical transfer learning technique, which uses a large \"source\" data set to drastically reduce the amount of data needed to perform well on a \"target\" site for which training data are scarce. We test this transfer technique with <i>AutoTriage</i>, a mortality prediction algorithm, on patient charts from the Beth Israel Deaconess Medical Center (the source) and a population of 48 249 adult inpatients from University of California San Francisco Medical Center (the target institution). We find that the amount of training data required to surpass 0.80 area under the receiver operating characteristic (AUROC) on the target set decreases from more than 4000 patients to fewer than 220. This performance is superior to the Modified Early Warning Score (AUROC: 0.76) and corresponds to a decrease in clinical data collection time from approximately 6 months to less than 10 days. Our results highlight the usefulness of transfer learning in the specialization of CDS systems to new hospital sites, without requiring expensive and time-consuming data collection efforts.</p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"9 ","pages":"1178222617712994"},"PeriodicalIF":0.0000,"publicationDate":"2017-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1177/1178222617712994","citationCount":"42","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/1178222617712994","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 42
Abstract
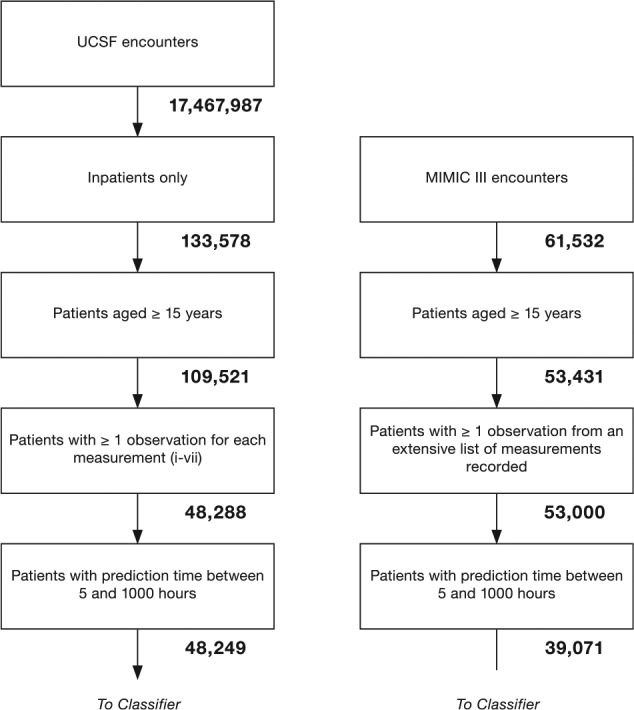
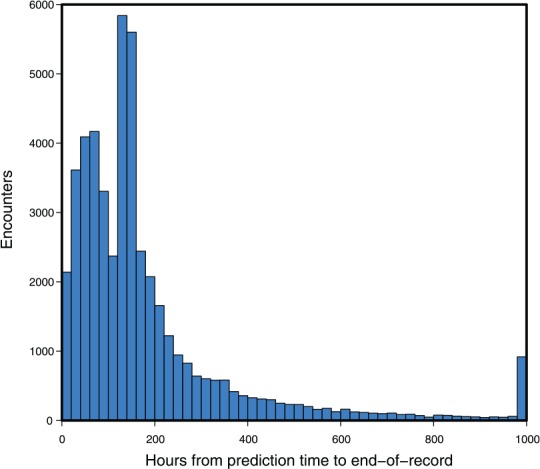
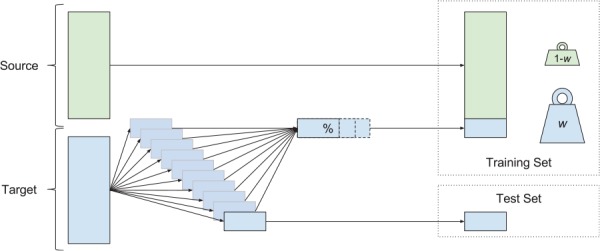
Algorithm-based clinical decision support (CDS) systems associate patient-derived health data with outcomes of interest, such as in-hospital mortality. However, the quality of such associations often depends on the availability of site-specific training data. Without sufficient quantities of data, the underlying statistical apparatus cannot differentiate useful patterns from noise and, as a result, may underperform. This initial training data burden limits the widespread, out-of-the-box, use of machine learning-based risk scoring systems. In this study, we implement a statistical transfer learning technique, which uses a large "source" data set to drastically reduce the amount of data needed to perform well on a "target" site for which training data are scarce. We test this transfer technique with AutoTriage, a mortality prediction algorithm, on patient charts from the Beth Israel Deaconess Medical Center (the source) and a population of 48 249 adult inpatients from University of California San Francisco Medical Center (the target institution). We find that the amount of training data required to surpass 0.80 area under the receiver operating characteristic (AUROC) on the target set decreases from more than 4000 patients to fewer than 220. This performance is superior to the Modified Early Warning Score (AUROC: 0.76) and corresponds to a decrease in clinical data collection time from approximately 6 months to less than 10 days. Our results highlight the usefulness of transfer learning in the specialization of CDS systems to new hospital sites, without requiring expensive and time-consuming data collection efforts.
基于算法的临床决策支持(CDS)系统将患者衍生的健康数据与感兴趣的结果(如住院死亡率)关联起来。然而,这种联系的质量往往取决于具体地点培训数据的可得性。如果没有足够数量的数据,底层的统计仪器就无法区分有用的模式和噪声,结果可能表现不佳。这种初始的训练数据负担限制了基于机器学习的风险评分系统的广泛使用。在本研究中,我们实现了一种统计迁移学习技术,该技术使用大型“源”数据集来大幅减少在训练数据稀缺的“目标”站点上表现良好所需的数据量。我们使用AutoTriage(一种死亡率预测算法)对来自Beth Israel Deaconess医疗中心(来源)的患者图表和来自加州大学旧金山医疗中心(目标机构)的48249名成年住院患者进行了测试。我们发现,在目标集的接收者操作特征(AUROC)下,超过0.80面积所需的训练数据量从4000多名患者减少到不到220名患者。这一性能优于改良早期预警评分(AUROC: 0.76),并对应于临床数据收集时间从大约6个月减少到不到10天。我们的研究结果强调了转移学习在CDS系统专业化到新医院的有用性,而不需要昂贵和耗时的数据收集工作。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


