{"title":"BCC-NER: bidirectional, contextual clues named entity tagger for gene/protein mention recognition.","authors":"Gurusamy Murugesan, Sabenabanu Abdulkadhar, Balu Bhasuran, Jeyakumar Natarajan","doi":"10.1186/s13637-017-0060-6","DOIUrl":null,"url":null,"abstract":"<p><p>Tagging biomedical entities such as gene, protein, cell, and cell-line is the first step and an important pre-requisite in biomedical literature mining. In this paper, we describe our hybrid named entity tagging approach namely BCC-NER (bidirectional, contextual clues named entity tagger for gene/protein mention recognition). BCC-NER is deployed with three modules. The first module is for text processing which includes basic NLP pre-processing, feature extraction, and feature selection. The second module is for training and model building with bidirectional conditional random fields (CRF) to parse the text in both directions (forward and backward) and integrate the backward and forward trained models using margin-infused relaxed algorithm (MIRA). The third and final module is for post-processing to achieve a better performance, which includes surrounding text features, parenthesis mismatching, and two-tier abbreviation algorithm. The evaluation results on BioCreative II GM test corpus of BCC-NER achieve a precision of 89.95, recall of 84.15 and overall F-score of 86.95, which is higher than the other currently available open source taggers.</p>","PeriodicalId":72957,"journal":{"name":"EURASIP journal on bioinformatics & systems biology","volume":"2017 1","pages":"7"},"PeriodicalIF":0.0000,"publicationDate":"2017-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13637-017-0060-6","citationCount":"18","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"EURASIP journal on bioinformatics & systems biology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s13637-017-0060-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2017/5/5 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 18
Abstract
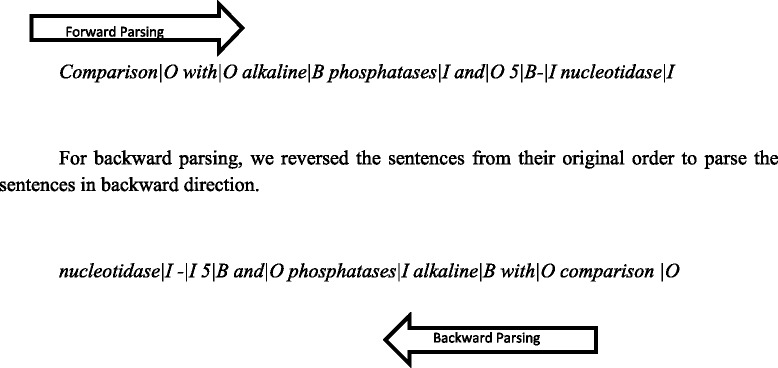
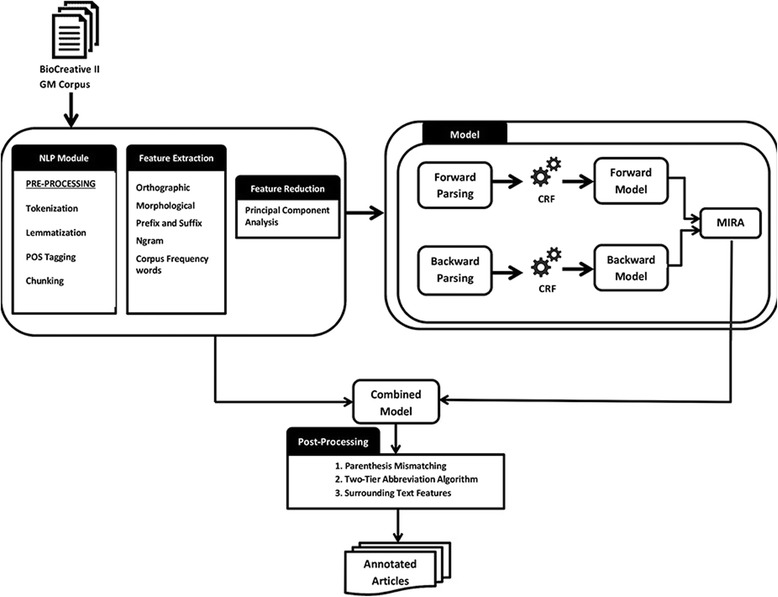
Tagging biomedical entities such as gene, protein, cell, and cell-line is the first step and an important pre-requisite in biomedical literature mining. In this paper, we describe our hybrid named entity tagging approach namely BCC-NER (bidirectional, contextual clues named entity tagger for gene/protein mention recognition). BCC-NER is deployed with three modules. The first module is for text processing which includes basic NLP pre-processing, feature extraction, and feature selection. The second module is for training and model building with bidirectional conditional random fields (CRF) to parse the text in both directions (forward and backward) and integrate the backward and forward trained models using margin-infused relaxed algorithm (MIRA). The third and final module is for post-processing to achieve a better performance, which includes surrounding text features, parenthesis mismatching, and two-tier abbreviation algorithm. The evaluation results on BioCreative II GM test corpus of BCC-NER achieve a precision of 89.95, recall of 84.15 and overall F-score of 86.95, which is higher than the other currently available open source taggers.
标记生物医学实体(如基因、蛋白质、细胞、细胞系)是生物医学文献挖掘的第一步,也是重要的先决条件。在本文中,我们描述了我们的混合命名实体标记方法,即BCC-NER(双向,上下文线索命名实体标记器用于基因/蛋白质提及识别)。BCC-NER部署了三个模块。第一个模块用于文本处理,包括基本的自然语言处理预处理、特征提取和特征选择。第二个模块是使用双向条件随机场(CRF)进行训练和模型构建,在两个方向(向前和向后)上解析文本,并使用边缘注入放松算法(MIRA)整合向后和向前训练的模型。第三个也是最后一个模块用于后处理,以获得更好的性能,其中包括围绕文本特征,括号不匹配和两层缩写算法。BCC-NER在BioCreative II GM测试语料库上的评价结果,准确率为89.95,召回率为84.15,总体f分为86.95,高于目前其他开源标注器。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


