Xiaofan Ding, Shui-Ying Tsang, Siu-Kin Ng, Hong Xue
{"title":"Application of Machine Learning to Development of Copy Number Variation-based Prediction of Cancer Risk.","authors":"Xiaofan Ding, Shui-Ying Tsang, Siu-Kin Ng, Hong Xue","doi":"10.4137/GEI.S15002","DOIUrl":null,"url":null,"abstract":"<p><p>In the present study, recurrent copy number variations (CNVs) from non-tumor blood cell DNAs of Caucasian non-cancer subjects and glioma, myeloma, and colorectal cancer-patients, and Korean non-cancer subjects and hepatocellular carcinoma, gastric cancer, and colorectal cancer patients, were found to reveal for each of the two ethnic cohorts highly significant differences between cancer patients and controls with respect to the number of CN-losses and size-distribution of CN-gains, suggesting the existence of recurrent constitutional CNV-features useful for prediction of predisposition to cancer. Upon identification by machine learning, such CNV-features could extensively discriminate between cancer-patient and control DNAs. When the CNV-features selected from a learning-group of Caucasian or Korean mixed DNAs consisting of both cancer-patient and control DNAs were employed to make predictions on the cancer predisposition of an unseen test group of mixed DNAs, the average prediction accuracy was 93.6% for the Caucasian cohort and 86.5% for the Korean cohort. </p>","PeriodicalId":88494,"journal":{"name":"Genomics insights","volume":"7 ","pages":"1-11"},"PeriodicalIF":0.0000,"publicationDate":"2014-06-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/GEI.S15002","citationCount":"18","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/GEI.S15002","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2014/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 18
Abstract
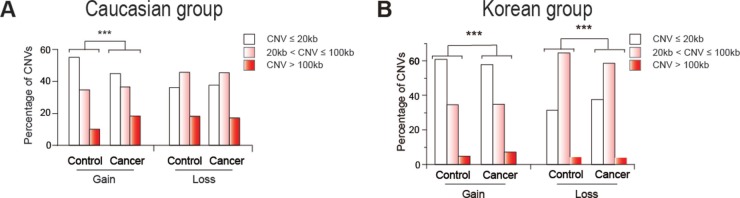
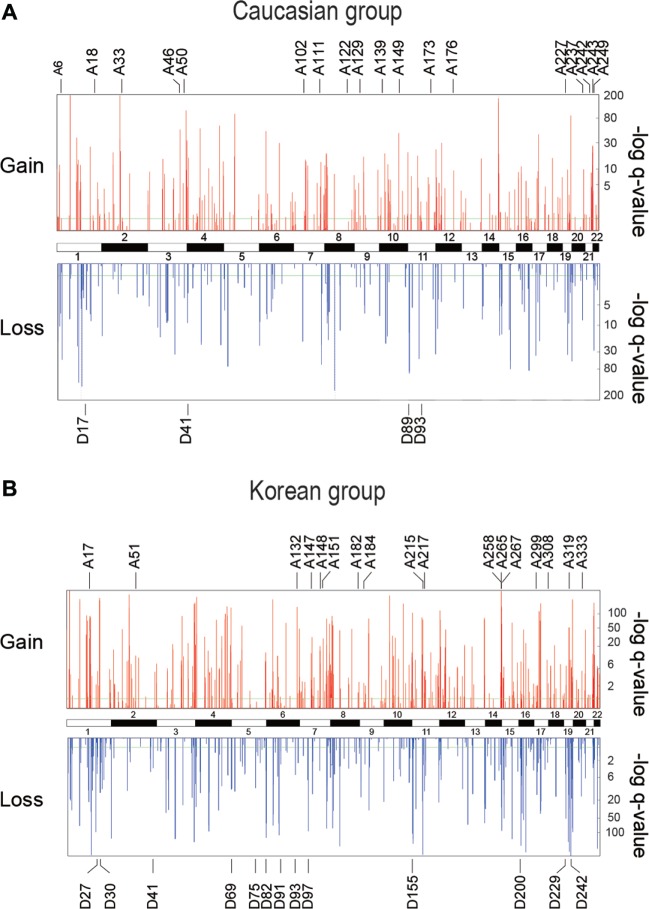
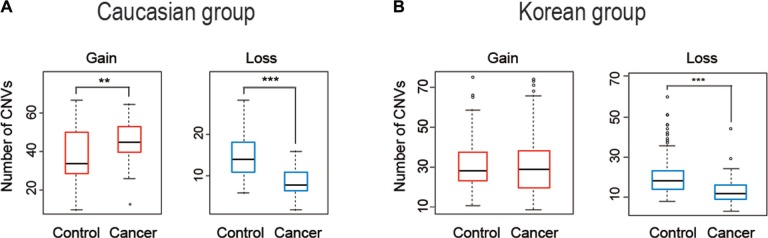
In the present study, recurrent copy number variations (CNVs) from non-tumor blood cell DNAs of Caucasian non-cancer subjects and glioma, myeloma, and colorectal cancer-patients, and Korean non-cancer subjects and hepatocellular carcinoma, gastric cancer, and colorectal cancer patients, were found to reveal for each of the two ethnic cohorts highly significant differences between cancer patients and controls with respect to the number of CN-losses and size-distribution of CN-gains, suggesting the existence of recurrent constitutional CNV-features useful for prediction of predisposition to cancer. Upon identification by machine learning, such CNV-features could extensively discriminate between cancer-patient and control DNAs. When the CNV-features selected from a learning-group of Caucasian or Korean mixed DNAs consisting of both cancer-patient and control DNAs were employed to make predictions on the cancer predisposition of an unseen test group of mixed DNAs, the average prediction accuracy was 93.6% for the Caucasian cohort and 86.5% for the Korean cohort.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


