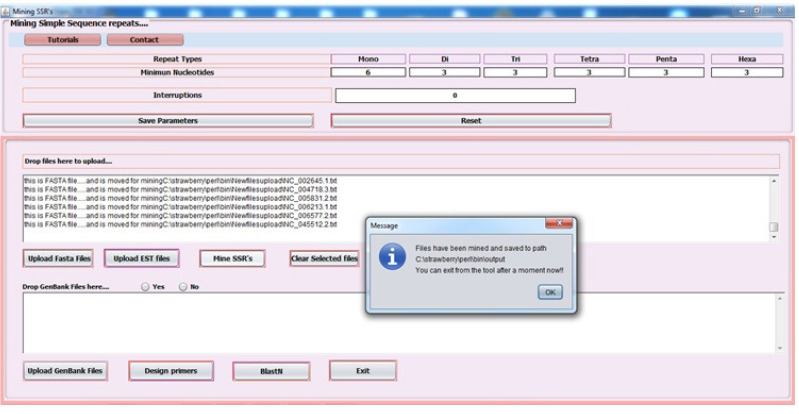
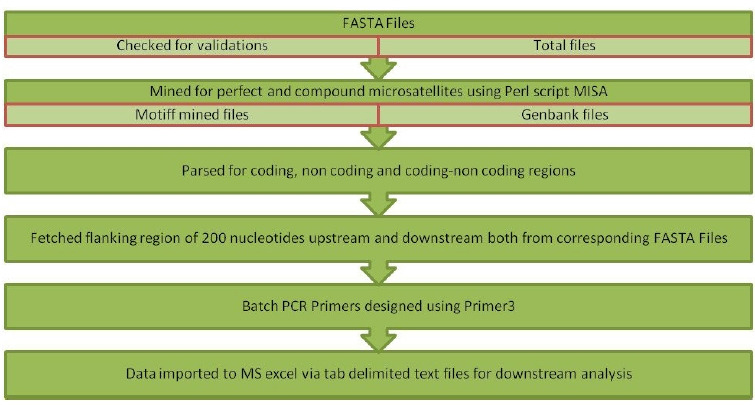
{"title":"Mining and analysis of microsatellites in human coronavirus genomes using the in-house built Java pipeline.","authors":"P K Bharti, Akhtar Husai","doi":"10.5808/gi.20033","DOIUrl":null,"url":null,"abstract":"<p><p>Microsatellites or simple sequence repeats are motifs of 1 to 6 nucleotides in length present in both coding and non-coding regions of DNA. These are found widely distributed in the whole genome of prokaryotes, eukaryotes, bacteria, and viruses and are used as molecular markers in studying DNA variations, gene regulation, genetic diversity and evolutionary studies, etc. However, in vitro microsatellite identification proves to be time-consuming and expensive. Therefore, the present research has been focused on using an in-house built java pipeline to identify, analyse, design primers and find related statistics of perfect and compound microsatellites in the seven complete genome sequences of coronavirus, including the genome of coronavirus disease 2019, where the host is Homo sapiens. Based on search criteria among seven genomic sequences, it was revealed that the total number of perfect simple sequence repeats (SSRs) found to be in the range of 76 to 118 and compound SSRs from 01 to10, thus reflecting the low conversion of perfect simple sequence to compound repeats. Furthermore, the incidence of SSRs was insignificant but positively correlated with genome size (R2 = 0.45, p > 0.05), with simple sequence repeats relative abundance (R2 = 0.18, p > 0.05) and relative density (R2 = 0.23, p > 0.05). Dinucleotide repeats were the most abundant in the coding region of the genome, followed by tri, mono, and tetra. This comparative study would help us understand the evolutionary relationship, genetic diversity, and hypervariability in minimal time and cost.</p>","PeriodicalId":36591,"journal":{"name":"Genomics and Informatics","volume":" ","pages":"e35"},"PeriodicalIF":0.0000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9576472/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Genomics and Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.5808/gi.20033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/9/30 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Agricultural and Biological Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
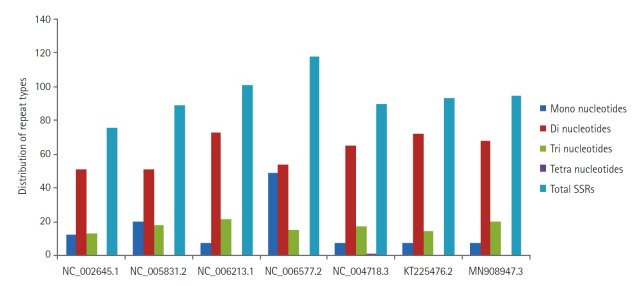
Microsatellites or simple sequence repeats are motifs of 1 to 6 nucleotides in length present in both coding and non-coding regions of DNA. These are found widely distributed in the whole genome of prokaryotes, eukaryotes, bacteria, and viruses and are used as molecular markers in studying DNA variations, gene regulation, genetic diversity and evolutionary studies, etc. However, in vitro microsatellite identification proves to be time-consuming and expensive. Therefore, the present research has been focused on using an in-house built java pipeline to identify, analyse, design primers and find related statistics of perfect and compound microsatellites in the seven complete genome sequences of coronavirus, including the genome of coronavirus disease 2019, where the host is Homo sapiens. Based on search criteria among seven genomic sequences, it was revealed that the total number of perfect simple sequence repeats (SSRs) found to be in the range of 76 to 118 and compound SSRs from 01 to10, thus reflecting the low conversion of perfect simple sequence to compound repeats. Furthermore, the incidence of SSRs was insignificant but positively correlated with genome size (R2 = 0.45, p > 0.05), with simple sequence repeats relative abundance (R2 = 0.18, p > 0.05) and relative density (R2 = 0.23, p > 0.05). Dinucleotide repeats were the most abundant in the coding region of the genome, followed by tri, mono, and tetra. This comparative study would help us understand the evolutionary relationship, genetic diversity, and hypervariability in minimal time and cost.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


