{"title":"A dedicated database system for handling multi-level data in systems biology.","authors":"Natapol Pornputtapong, Kwanjeera Wanichthanarak, Avlant Nilsson, Intawat Nookaew, Jens Nielsen","doi":"10.1186/1751-0473-9-17","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Advances in high-throughput technologies have enabled extensive generation of multi-level omics data. These data are crucial for systems biology research, though they are complex, heterogeneous, highly dynamic, incomplete and distributed among public databases. This leads to difficulties in data accessibility and often results in errors when data are merged and integrated from varied resources. Therefore, integration and management of systems biological data remain very challenging.</p><p><strong>Methods: </strong>To overcome this, we designed and developed a dedicated database system that can serve and solve the vital issues in data management and hereby facilitate data integration, modeling and analysis in systems biology within a sole database. In addition, a yeast data repository was implemented as an integrated database environment which is operated by the database system. Two applications were implemented to demonstrate extensibility and utilization of the system. Both illustrate how the user can access the database via the web query function and implemented scripts. These scripts are specific for two sample cases: 1) Detecting the pheromone pathway in protein interaction networks; and 2) Finding metabolic reactions regulated by Snf1 kinase.</p><p><strong>Results and conclusion: </strong>In this study we present the design of database system which offers an extensible environment to efficiently capture the majority of biological entities and relations encountered in systems biology. Critical functions and control processes were designed and implemented to ensure consistent, efficient, secure and reliable transactions. The two sample cases on the yeast integrated data clearly demonstrate the value of a sole database environment for systems biology research.</p>","PeriodicalId":35052,"journal":{"name":"Source Code for Biology and Medicine","volume":"9 ","pages":"17"},"PeriodicalIF":0.0000,"publicationDate":"2014-07-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1751-0473-9-17","citationCount":"2","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Source Code for Biology and Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1751-0473-9-17","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2014/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"Decision Sciences","Score":null,"Total":0}
引用次数: 2
Abstract
Background: Advances in high-throughput technologies have enabled extensive generation of multi-level omics data. These data are crucial for systems biology research, though they are complex, heterogeneous, highly dynamic, incomplete and distributed among public databases. This leads to difficulties in data accessibility and often results in errors when data are merged and integrated from varied resources. Therefore, integration and management of systems biological data remain very challenging.
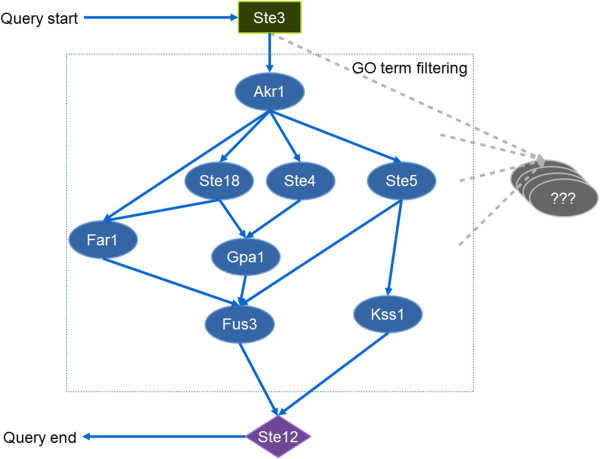
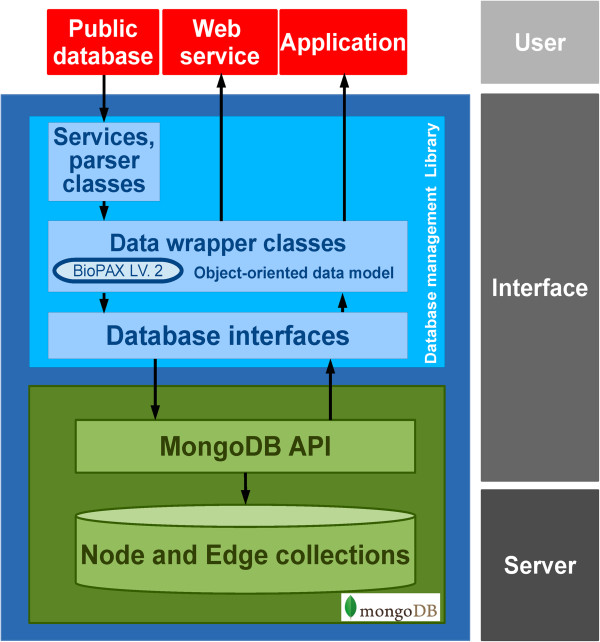
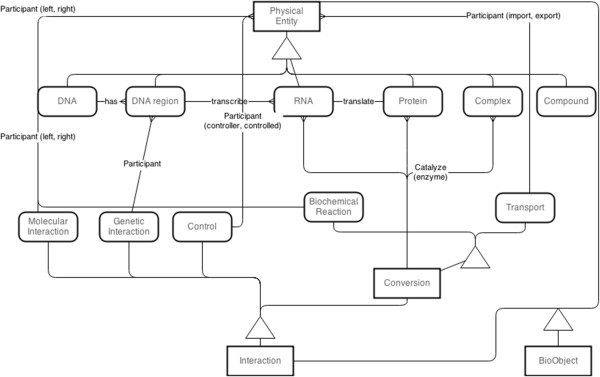
Methods: To overcome this, we designed and developed a dedicated database system that can serve and solve the vital issues in data management and hereby facilitate data integration, modeling and analysis in systems biology within a sole database. In addition, a yeast data repository was implemented as an integrated database environment which is operated by the database system. Two applications were implemented to demonstrate extensibility and utilization of the system. Both illustrate how the user can access the database via the web query function and implemented scripts. These scripts are specific for two sample cases: 1) Detecting the pheromone pathway in protein interaction networks; and 2) Finding metabolic reactions regulated by Snf1 kinase.
Results and conclusion: In this study we present the design of database system which offers an extensible environment to efficiently capture the majority of biological entities and relations encountered in systems biology. Critical functions and control processes were designed and implemented to ensure consistent, efficient, secure and reliable transactions. The two sample cases on the yeast integrated data clearly demonstrate the value of a sole database environment for systems biology research.
期刊介绍:
Source Code for Biology and Medicine is a peer-reviewed open access, online journal that publishes articles on source code employed over a wide range of applications in biology and medicine. The journal"s aim is to publish source code for distribution and use in the public domain in order to advance biological and medical research. Through this dissemination, it may be possible to shorten the time required for solving certain computational problems for which there is limited source code availability or resources.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


