{"title":"Plant MicroRNA Prediction by Supervised Machine Learning Using C5.0 Decision Trees.","authors":"Philip H Williams, Rod Eyles, Georg Weiller","doi":"10.1155/2012/652979","DOIUrl":null,"url":null,"abstract":"<p><p>MicroRNAs (miRNAs) are nonprotein coding RNAs between 20 and 22 nucleotides long that attenuate protein production. Different types of sequence data are being investigated for novel miRNAs, including genomic and transcriptomic sequences. A variety of machine learning methods have successfully predicted miRNA precursors, mature miRNAs, and other nonprotein coding sequences. MirTools, mirDeep2, and miRanalyzer require \"read count\" to be included with the input sequences, which restricts their use to deep-sequencing data. Our aim was to train a predictor using a cross-section of different species to accurately predict miRNAs outside the training set. We wanted a system that did not require read-count for prediction and could therefore be applied to short sequences extracted from genomic, EST, or RNA-seq sources. A miRNA-predictive decision-tree model has been developed by supervised machine learning. It only requires that the corresponding genome or transcriptome is available within a sequence window that includes the precursor candidate so that the required sequence features can be collected. Some of the most critical features for training the predictor are the miRNA:miRNA(∗) duplex energy and the number of mismatches in the duplex. We present a cross-species plant miRNA predictor with 84.08% sensitivity and 98.53% specificity based on rigorous testing by leave-one-out validation.</p>","PeriodicalId":16575,"journal":{"name":"Journal of Nucleic Acids","volume":"2012 ","pages":"652979"},"PeriodicalIF":1.3000,"publicationDate":"2012-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3503367/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Nucleic Acids","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1155/2012/652979","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2012/11/7 0:00:00","PubModel":"Epub","JCR":"Q4","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
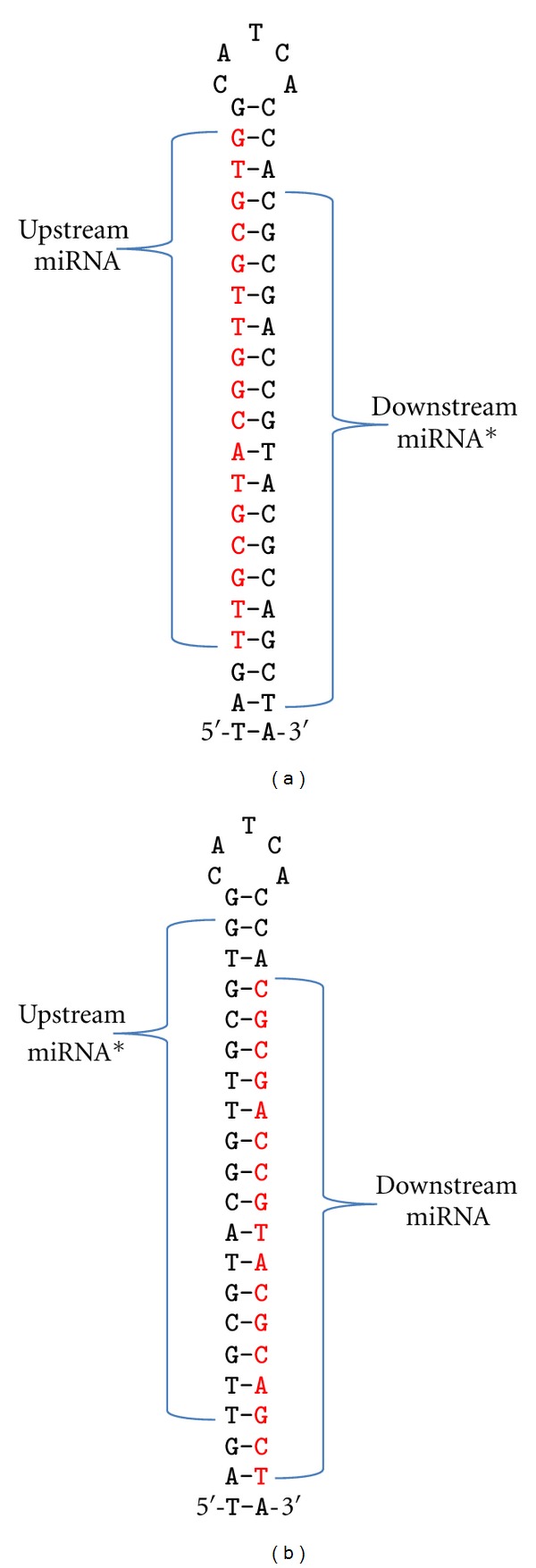
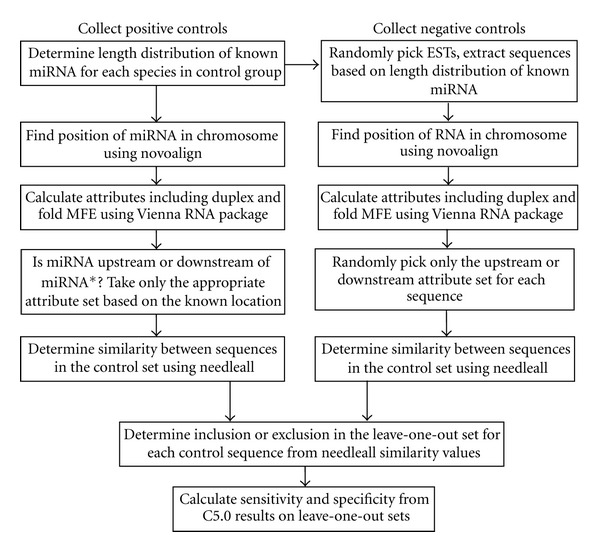
MicroRNAs (miRNAs) are nonprotein coding RNAs between 20 and 22 nucleotides long that attenuate protein production. Different types of sequence data are being investigated for novel miRNAs, including genomic and transcriptomic sequences. A variety of machine learning methods have successfully predicted miRNA precursors, mature miRNAs, and other nonprotein coding sequences. MirTools, mirDeep2, and miRanalyzer require "read count" to be included with the input sequences, which restricts their use to deep-sequencing data. Our aim was to train a predictor using a cross-section of different species to accurately predict miRNAs outside the training set. We wanted a system that did not require read-count for prediction and could therefore be applied to short sequences extracted from genomic, EST, or RNA-seq sources. A miRNA-predictive decision-tree model has been developed by supervised machine learning. It only requires that the corresponding genome or transcriptome is available within a sequence window that includes the precursor candidate so that the required sequence features can be collected. Some of the most critical features for training the predictor are the miRNA:miRNA(∗) duplex energy and the number of mismatches in the duplex. We present a cross-species plant miRNA predictor with 84.08% sensitivity and 98.53% specificity based on rigorous testing by leave-one-out validation.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


