Wenbo Wang, Lu Chen, Ming Tan, Shaojun Wang, Amit P Sheth
{"title":"Discovering Fine-grained Sentiment in Suicide Notes.","authors":"Wenbo Wang, Lu Chen, Ming Tan, Shaojun Wang, Amit P Sheth","doi":"10.4137/BII.S8963","DOIUrl":null,"url":null,"abstract":"<p><p>This paper presents our solution for the i2b2 sentiment classification challenge. Our hybrid system consists of machine learning and rule-based classifiers. For the machine learning classifier, we investigate a variety of lexical, syntactic and knowledge-based features, and show how much these features contribute to the performance of the classifier through experiments. For the rule-based classifier, we propose an algorithm to automatically extract effective syntactic and lexical patterns from training examples. The experimental results show that the rule-based classifier outperforms the baseline machine learning classifier using unigram features. By combining the machine learning classifier and the rule-based classifier, the hybrid system gains a better trade-off between precision and recall, and yields the highest micro-averaged F-measure (0.5038), which is better than the mean (0.4875) and median (0.5027) micro-average F-measures among all participating teams.</p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"5 Suppl. 1","pages":"137-45"},"PeriodicalIF":0.0000,"publicationDate":"2012-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/BII.S8963","citationCount":"24","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/BII.S8963","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2012/1/30 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 24
Abstract
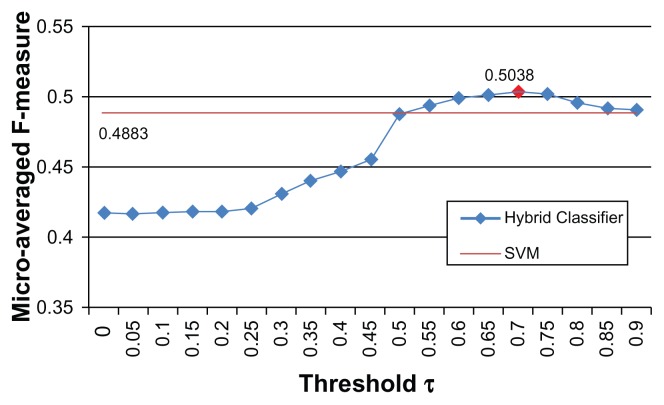
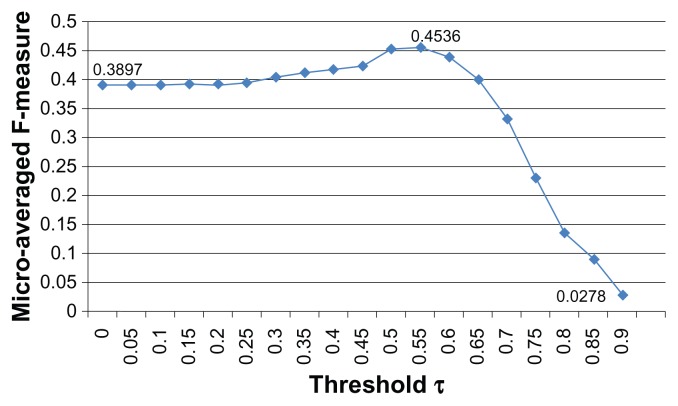
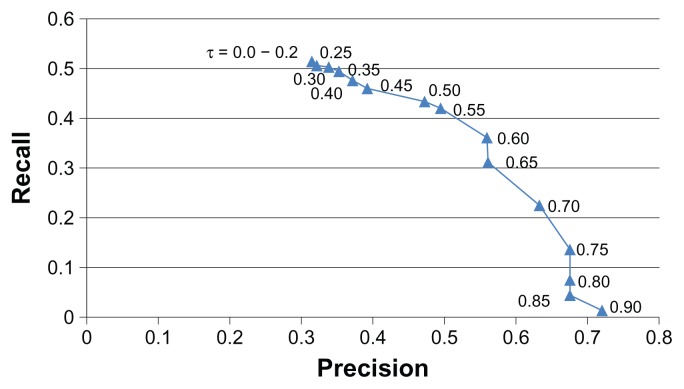
This paper presents our solution for the i2b2 sentiment classification challenge. Our hybrid system consists of machine learning and rule-based classifiers. For the machine learning classifier, we investigate a variety of lexical, syntactic and knowledge-based features, and show how much these features contribute to the performance of the classifier through experiments. For the rule-based classifier, we propose an algorithm to automatically extract effective syntactic and lexical patterns from training examples. The experimental results show that the rule-based classifier outperforms the baseline machine learning classifier using unigram features. By combining the machine learning classifier and the rule-based classifier, the hybrid system gains a better trade-off between precision and recall, and yields the highest micro-averaged F-measure (0.5038), which is better than the mean (0.4875) and median (0.5027) micro-average F-measures among all participating teams.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


