Francisco M Couto, Mário J Silva, Vivian Lee, Emily Dimmer, Evelyn Camon, Rolf Apweiler, Harald Kirsch, Dietrich Rebholz-Schuhmann
{"title":"GOAnnotator: linking protein GO annotations to evidence text.","authors":"Francisco M Couto, Mário J Silva, Vivian Lee, Emily Dimmer, Evelyn Camon, Rolf Apweiler, Harald Kirsch, Dietrich Rebholz-Schuhmann","doi":"10.1186/1747-5333-1-19","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Annotation of proteins with gene ontology (GO) terms is ongoing work and a complex task. Manual GO annotation is precise and precious, but it is time-consuming. Therefore, instead of curated annotations most of the proteins come with uncurated annotations, which have been generated automatically. Text-mining systems that use literature for automatic annotation have been proposed but they do not satisfy the high quality expectations of curators.</p><p><strong>Results: </strong>In this paper we describe an approach that links uncurated annotations to text extracted from literature. The selection of the text is based on the similarity of the text to the term from the uncurated annotation. Besides substantiating the uncurated annotations, the extracted texts also lead to novel annotations. In addition, the approach uses the GO hierarchy to achieve high precision. Our approach is integrated into GOAnnotator, a tool that assists the curation process for GO annotation of UniProt proteins.</p><p><strong>Conclusion: </strong>The GO curators assessed GOAnnotator with a set of 66 distinct UniProt/SwissProt proteins with uncurated annotations. GOAnnotator provided correct evidence text at 93% precision. This high precision results from using the GO hierarchy to only select GO terms similar to GO terms from uncurated annotations in GOA. Our approach is the first one to achieve high precision, which is crucial for the efficient support of GO curators. GOAnnotator was implemented as a web tool that is freely available at http://xldb.di.fc.ul.pt/rebil/tools/goa/.</p>","PeriodicalId":87404,"journal":{"name":"Journal of biomedical discovery and collaboration","volume":"1 ","pages":"19"},"PeriodicalIF":0.0000,"publicationDate":"2006-12-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1747-5333-1-19","citationCount":"73","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of biomedical discovery and collaboration","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1747-5333-1-19","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 73
Abstract
Background: Annotation of proteins with gene ontology (GO) terms is ongoing work and a complex task. Manual GO annotation is precise and precious, but it is time-consuming. Therefore, instead of curated annotations most of the proteins come with uncurated annotations, which have been generated automatically. Text-mining systems that use literature for automatic annotation have been proposed but they do not satisfy the high quality expectations of curators.
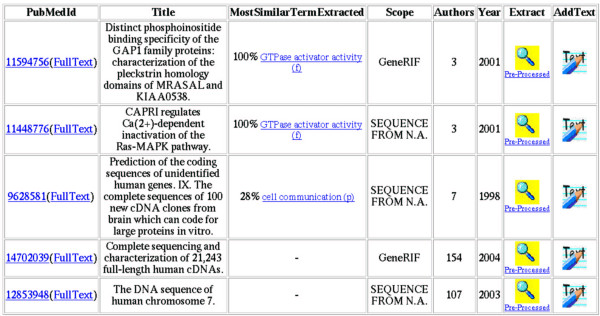
Results: In this paper we describe an approach that links uncurated annotations to text extracted from literature. The selection of the text is based on the similarity of the text to the term from the uncurated annotation. Besides substantiating the uncurated annotations, the extracted texts also lead to novel annotations. In addition, the approach uses the GO hierarchy to achieve high precision. Our approach is integrated into GOAnnotator, a tool that assists the curation process for GO annotation of UniProt proteins.
Conclusion: The GO curators assessed GOAnnotator with a set of 66 distinct UniProt/SwissProt proteins with uncurated annotations. GOAnnotator provided correct evidence text at 93% precision. This high precision results from using the GO hierarchy to only select GO terms similar to GO terms from uncurated annotations in GOA. Our approach is the first one to achieve high precision, which is crucial for the efficient support of GO curators. GOAnnotator was implemented as a web tool that is freely available at http://xldb.di.fc.ul.pt/rebil/tools/goa/.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


