{"title":"Fast lightweight accurate xenograft sorting.","authors":"Jens Zentgraf, Sven Rahmann","doi":"10.1186/s13015-021-00181-w","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>With an increasing number of patient-derived xenograft (PDX) models being created and subsequently sequenced to study tumor heterogeneity and to guide therapy decisions, there is a similarly increasing need for methods to separate reads originating from the graft (human) tumor and reads originating from the host species' (mouse) surrounding tissue. Two kinds of methods are in use: On the one hand, alignment-based tools require that reads are mapped and aligned (by an external mapper/aligner) to the host and graft genomes separately first; the tool itself then processes the resulting alignments and quality metrics (typically BAM files) to assign each read or read pair. On the other hand, alignment-free tools work directly on the raw read data (typically FASTQ files). Recent studies compare different approaches and tools, with varying results.</p><p><strong>Results: </strong>We show that alignment-free methods for xenograft sorting are superior concerning CPU time usage and equivalent in accuracy. We improve upon the state of the art sorting by presenting a fast lightweight approach based on three-way bucketed quotiented Cuckoo hashing. Our hash table requires memory comparable to an FM index typically used for read alignment and less than other alignment-free approaches. It allows extremely fast lookups and uses less CPU time than other alignment-free methods and alignment-based methods at similar accuracy. Several engineering steps (e.g., shortcuts for unsuccessful lookups, software prefetching) improve the performance even further.</p><p><strong>Availability: </strong>Our software xengsort is available under the MIT license at http://gitlab.com/genomeinformatics/xengsort . It is written in numba-compiled Python and comes with sample Snakemake workflows for hash table construction and dataset processing.</p>","PeriodicalId":50823,"journal":{"name":"Algorithms for Molecular Biology","volume":"16 1","pages":"2"},"PeriodicalIF":1.7000,"publicationDate":"2021-04-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13015-021-00181-w","citationCount":"8","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Algorithms for Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13015-021-00181-w","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 8
Abstract
Motivation: With an increasing number of patient-derived xenograft (PDX) models being created and subsequently sequenced to study tumor heterogeneity and to guide therapy decisions, there is a similarly increasing need for methods to separate reads originating from the graft (human) tumor and reads originating from the host species' (mouse) surrounding tissue. Two kinds of methods are in use: On the one hand, alignment-based tools require that reads are mapped and aligned (by an external mapper/aligner) to the host and graft genomes separately first; the tool itself then processes the resulting alignments and quality metrics (typically BAM files) to assign each read or read pair. On the other hand, alignment-free tools work directly on the raw read data (typically FASTQ files). Recent studies compare different approaches and tools, with varying results.
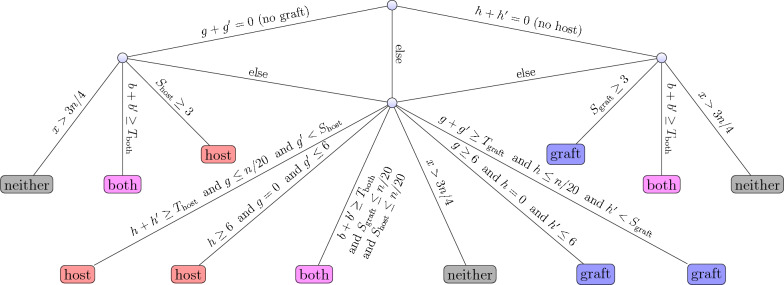
Results: We show that alignment-free methods for xenograft sorting are superior concerning CPU time usage and equivalent in accuracy. We improve upon the state of the art sorting by presenting a fast lightweight approach based on three-way bucketed quotiented Cuckoo hashing. Our hash table requires memory comparable to an FM index typically used for read alignment and less than other alignment-free approaches. It allows extremely fast lookups and uses less CPU time than other alignment-free methods and alignment-based methods at similar accuracy. Several engineering steps (e.g., shortcuts for unsuccessful lookups, software prefetching) improve the performance even further.
Availability: Our software xengsort is available under the MIT license at http://gitlab.com/genomeinformatics/xengsort . It is written in numba-compiled Python and comes with sample Snakemake workflows for hash table construction and dataset processing.
期刊介绍:
Algorithms for Molecular Biology publishes articles on novel algorithms for biological sequence and structure analysis, phylogeny reconstruction, and combinatorial algorithms and machine learning.
Areas of interest include but are not limited to: algorithms for RNA and protein structure analysis, gene prediction and genome analysis, comparative sequence analysis and alignment, phylogeny, gene expression, machine learning, and combinatorial algorithms.
Where appropriate, manuscripts should describe applications to real-world data. However, pure algorithm papers are also welcome if future applications to biological data are to be expected, or if they address complexity or approximation issues of novel computational problems in molecular biology. Articles about novel software tools will be considered for publication if they contain some algorithmically interesting aspects.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


