{"title":"A forecasting method with efficient selection of variables in multivariate data sets.","authors":"Pinki Sagar, Prinima Gupta, Indu Kashyap","doi":"10.1007/s41870-021-00619-9","DOIUrl":null,"url":null,"abstract":"<p><p>Regression is a kind of data analysis technique in which the relationship between the independent variable(x) and dependent variable(y) is modeled and for polynomial regression it is up to the nth degree polynomial. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted by E (y|x). In this paper polynomial regression analysis has been improved through efficient selection of variables that is coefficient of determination. Coefficient of determination is a square of the correlation between new predicted y values and actual y values and its values are in the range from 0 to 1. The main purpose of regression analysis is to discover the relationship among the independent and dependent variables or in other words it is an explanation of variation in one variable with another variable. In this paper, the main focus is on Multivariate data sets that have many attributes and it is not necessary that all variables are required for data analysis purposes. Using coefficient of determination (COD) irrelevant attributes get eliminated during analysis. The main objective of research is to reduce the cost of data maintenance, reduce the execution time and improve the prediction accuracy rate. COD helps in selecting suitable independent variables. It is a notch that is used in statistical analysis that assesses how well a model explains and forecasts upcoming outcomes. This method also helps in eliminating the irrelevant variables which are not required for the prediction model by this maintenance cost and size of data sets can be reduced.</p>","PeriodicalId":73455,"journal":{"name":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","volume":"13 3","pages":"1039-1046"},"PeriodicalIF":0.0000,"publicationDate":"2021-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1007/s41870-021-00619-9","citationCount":"3","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of information technology : an official journal of Bharati Vidyapeeth's Institute of Computer Applications and Management","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41870-021-00619-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/2/28 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 3
Abstract
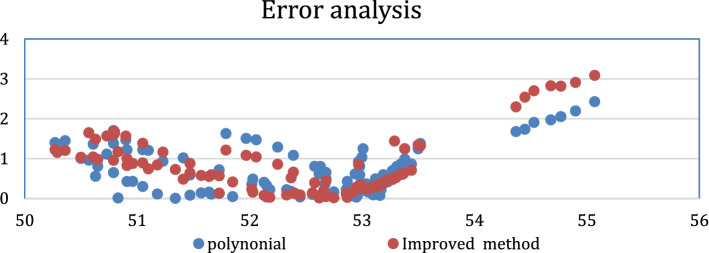
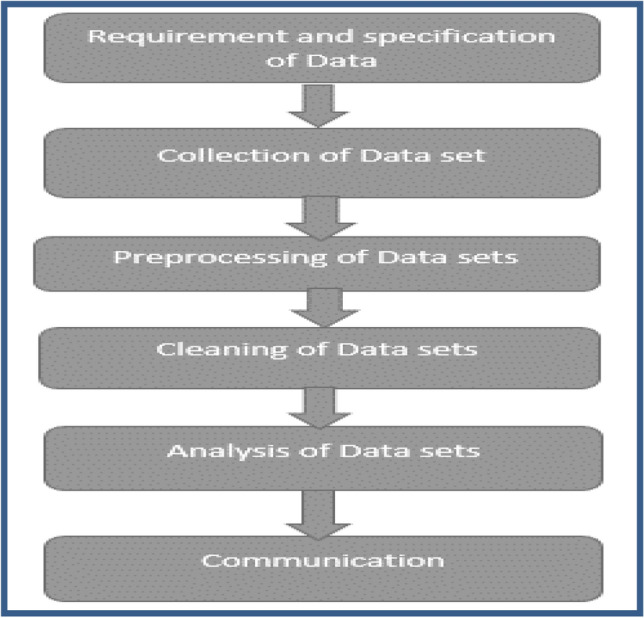
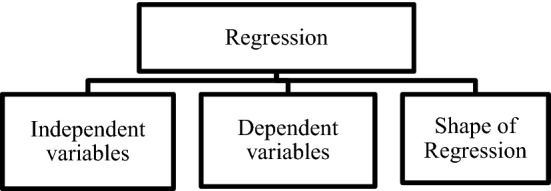
Regression is a kind of data analysis technique in which the relationship between the independent variable(x) and dependent variable(y) is modeled and for polynomial regression it is up to the nth degree polynomial. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted by E (y|x). In this paper polynomial regression analysis has been improved through efficient selection of variables that is coefficient of determination. Coefficient of determination is a square of the correlation between new predicted y values and actual y values and its values are in the range from 0 to 1. The main purpose of regression analysis is to discover the relationship among the independent and dependent variables or in other words it is an explanation of variation in one variable with another variable. In this paper, the main focus is on Multivariate data sets that have many attributes and it is not necessary that all variables are required for data analysis purposes. Using coefficient of determination (COD) irrelevant attributes get eliminated during analysis. The main objective of research is to reduce the cost of data maintenance, reduce the execution time and improve the prediction accuracy rate. COD helps in selecting suitable independent variables. It is a notch that is used in statistical analysis that assesses how well a model explains and forecasts upcoming outcomes. This method also helps in eliminating the irrelevant variables which are not required for the prediction model by this maintenance cost and size of data sets can be reduced.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


