{"title":"Are all models wrong?","authors":"Heiko Enderling, Olaf Wolkenhauer","doi":"10.1002/cso2.1008","DOIUrl":null,"url":null,"abstract":"<p>Mathematical modeling in cancer is enjoying a rapid expansion [<span>1</span>]. For collegial discussion across disciplines, many—if not all of us—have used the aphorism that “<i>All models are wrong, but some are useful</i>” [<span>2</span>]. This has been a convenient approach to justify and communicate the praxis of modeling. This is to suggest that the <i>usefulness</i> of a model is not measured by the accuracy of representation but how well it supports the generation, testing, and refinement of hypotheses. A key insight is not to focus on the model as an outcome, but to consider the modeling process and simulated model predictions as “ways of thinking” about complex nonlinear dynamical systems [<span>3</span>]. Here, we discuss the convoluted interpretation of <i>models being wrong</i> in the arena of predictive modeling.</p><p>“<i>All models are wrong, but some are useful</i>” emphasizes the value of abstraction in order to gain insight. While abstraction clearly implies misrepresentation, it allows to explicitly define model assumptions and interpret model results within these limitations – <i>Truth emerges more readily from error than from confusion</i> [<span>4</span>]. It is thus the process of modeling and the discussions about model assumptions that are often considered most valuable in interdisciplinary research. They provide a way of thinking about complex systems and mechanisms underlying observations. Abstractions are being made in cancer biology for every experiment in each laboratory around the world. In vitro cell lines or in vivo mouse experiments are abstractions of complex adaptive evolving human cancers in the complex adaptive dynamic environment called the patient. These \"wet lab\" experiments akin to \"dry lab\" mathematical models offer confirmation or refutation of hypotheses and results, which have to be prospectively evaluated in clinical trials before conclusions can be generalized beyond the abstracted assumptions. The key for any model—mathematical, biological, or clinical—to succeed is an iterative cycle of data-driven modeling and model-driven experimentation [<span>5, 6</span>]. The value of such an effort lies in the insights about mechanisms that can then be attributed to the considered variables [<span>7</span>]. With simplified representations of a system one can learn about the emergence of general patterns, like the occurrence of oscillations, bistability, or chaos [<span>8-10</span>].</p><p>In this context, Alan Turing framed the purpose of a mathematical model in his seminal paper about “The chemical basis of morphogenesis” [<span>11</span>] with “<i>This model will be a simplification and an idealization, and consequently a falsification. It is to be hoped that the features retained for discussion are those of greatest importance in the present state of knowledge</i>.” For many mathematical biology models that are built to explore, test, and generate hypotheses about emerging dynamics, this remains true. “<i>Wrong models</i>” allow us to reevaluate our assumptions, and the lessons learned from these discussions can help formulate revised models and improve our understanding of the underlying dynamics.</p><p>However, mathematical oncology models are deployed not only to simulate emergent properties of complex systems to generate, test, and refine hypotheses, but increasingly also with the intent to make predictions—often how an individual cancer patient will respond to a specific treatment [1]. For predictive modeling, the aphorism “<i>All models are wrong</i>” becomes awkward. In the predictive modeling arena, a <i>useful</i> model should <i>not</i> be <i>wrong</i>. A major hurdle in the application of predictive modeling, in general and in oncology in particular, is communication of model purpose and prediction uncertainty, and how likelihood and risks are interpreted by the end user. With limited data available about a complex adaptive evolving system, “forecasting failures” are common when events that are not represented in the data dominate the subsequent behavior (such as emergence of treatment resistance not being represented in pre-treatment dynamics). If predictive models are trained on historic data but with little patient-specific data over multiple time points, what role could predictive models play in oncology?</p><p>Computer simulations of mathematical models that are based on limited data are merely visualizing plausible disease trajectories forward in time. Predictions could then be made from analyzing the possible trajectories using multiple plausible parameter combinations, from either a single model or multiple models with competing assumptions and different weighting of likely important factors. While in some domains, such as hurricane trajectory forecasts, we trust mathematical models and accept their inherent, well-documented prediction uncertainties [<span>12</span>], it is imperative to improve the communication of what models can and cannot do when it comes to personal health. “<i>Nothing is more difficult to predict than the future</i>1,” and while the uncertainty linked to predictions rises quickly, we may still find use in the model.</p><p>For clinical purpose, predictive models may not need to accurately describe the complex biology of cancer, but to provide a trigger for decision making, often upon binary endpoints. For many years, we have set ourselves the lofty goal of predicting the tumor burden evolution during treatment with ever decreasing error to the actual data [<span>14-16</span>]; yet the clinical endpoint for patients is often not the actual tumor volume dynamics but binary endpoints such as continuous response or cancer progression, tumor control or treatment failure. Machine learning approaches (or simple statistics) can identify threshold values for tumor burden at different time points during therapy that stratify patients into the different outcomes [<span>17-19</span>]. Then, the model purpose becomes to accurately predict whether a tumor will shrink below this threshold or not. A larger error to the data but a correct outcome classification becomes an acceptable tradeoff for better fits but incorrect predictions. With this understanding, we have seen unprecedented model <i>prediction accuracy</i> for individual patients from few response measurements early during therapy [<span>18</span>]. The dilemma is visualized in Figure 1. For both patients, one head and neck cancer patient treated with radiotherapy and one prostate cancer patient treated with intermittent hormone therapy, only a few of the 100 predicted disease trajectories each mimic the eventual clinically observed dynamics. Yet, the majority of the simulations accurately predict disease burden to be above or to be below the learned thresholds for tumor control or treatment resistance.</p><p>Modeling efforts support various goals, linked to different expectation as to what modeling provides to a specific project. For the application of mathematical modeling for personalized medicine, further discussions about what models can and cannot contribute are necessary. For predictive modeling, <i>right</i> or <i>wrong</i> may not be how well the predicted disease dynamics based on uncertain parameter combinations mimic the clinically observed responses and their underlying biology, but the interpretation and actionability of model predictions and their uncertainty. While mathematical models may not be <i>right</i>, they do not have to be <i>wrong</i>. Thus, we may just adopt the philosophy of Assistant Director of Operations Domingo “Ding” Chavez, who taught the young Jack Ryan, Jr., in Tom Clancy's Oath of Office to “<i>Don't practice until you get it right. Practice until you don't get it wrong</i>” [<span>20</span>].</p>","PeriodicalId":72658,"journal":{"name":"Computational and systems oncology","volume":"1 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2021-01-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1002/cso2.1008","citationCount":"48","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and systems oncology","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cso2.1008","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 48
Abstract
Mathematical modeling in cancer is enjoying a rapid expansion [1]. For collegial discussion across disciplines, many—if not all of us—have used the aphorism that “All models are wrong, but some are useful” [2]. This has been a convenient approach to justify and communicate the praxis of modeling. This is to suggest that the usefulness of a model is not measured by the accuracy of representation but how well it supports the generation, testing, and refinement of hypotheses. A key insight is not to focus on the model as an outcome, but to consider the modeling process and simulated model predictions as “ways of thinking” about complex nonlinear dynamical systems [3]. Here, we discuss the convoluted interpretation of models being wrong in the arena of predictive modeling.
“All models are wrong, but some are useful” emphasizes the value of abstraction in order to gain insight. While abstraction clearly implies misrepresentation, it allows to explicitly define model assumptions and interpret model results within these limitations – Truth emerges more readily from error than from confusion [4]. It is thus the process of modeling and the discussions about model assumptions that are often considered most valuable in interdisciplinary research. They provide a way of thinking about complex systems and mechanisms underlying observations. Abstractions are being made in cancer biology for every experiment in each laboratory around the world. In vitro cell lines or in vivo mouse experiments are abstractions of complex adaptive evolving human cancers in the complex adaptive dynamic environment called the patient. These "wet lab" experiments akin to "dry lab" mathematical models offer confirmation or refutation of hypotheses and results, which have to be prospectively evaluated in clinical trials before conclusions can be generalized beyond the abstracted assumptions. The key for any model—mathematical, biological, or clinical—to succeed is an iterative cycle of data-driven modeling and model-driven experimentation [5, 6]. The value of such an effort lies in the insights about mechanisms that can then be attributed to the considered variables [7]. With simplified representations of a system one can learn about the emergence of general patterns, like the occurrence of oscillations, bistability, or chaos [8-10].
In this context, Alan Turing framed the purpose of a mathematical model in his seminal paper about “The chemical basis of morphogenesis” [11] with “This model will be a simplification and an idealization, and consequently a falsification. It is to be hoped that the features retained for discussion are those of greatest importance in the present state of knowledge.” For many mathematical biology models that are built to explore, test, and generate hypotheses about emerging dynamics, this remains true. “Wrong models” allow us to reevaluate our assumptions, and the lessons learned from these discussions can help formulate revised models and improve our understanding of the underlying dynamics.
However, mathematical oncology models are deployed not only to simulate emergent properties of complex systems to generate, test, and refine hypotheses, but increasingly also with the intent to make predictions—often how an individual cancer patient will respond to a specific treatment [1]. For predictive modeling, the aphorism “All models are wrong” becomes awkward. In the predictive modeling arena, a useful model should not be wrong. A major hurdle in the application of predictive modeling, in general and in oncology in particular, is communication of model purpose and prediction uncertainty, and how likelihood and risks are interpreted by the end user. With limited data available about a complex adaptive evolving system, “forecasting failures” are common when events that are not represented in the data dominate the subsequent behavior (such as emergence of treatment resistance not being represented in pre-treatment dynamics). If predictive models are trained on historic data but with little patient-specific data over multiple time points, what role could predictive models play in oncology?
Computer simulations of mathematical models that are based on limited data are merely visualizing plausible disease trajectories forward in time. Predictions could then be made from analyzing the possible trajectories using multiple plausible parameter combinations, from either a single model or multiple models with competing assumptions and different weighting of likely important factors. While in some domains, such as hurricane trajectory forecasts, we trust mathematical models and accept their inherent, well-documented prediction uncertainties [12], it is imperative to improve the communication of what models can and cannot do when it comes to personal health. “Nothing is more difficult to predict than the future1,” and while the uncertainty linked to predictions rises quickly, we may still find use in the model.
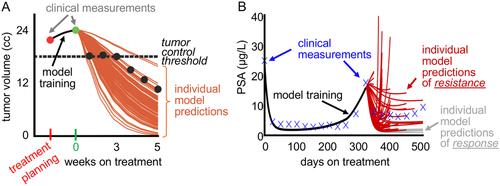
For clinical purpose, predictive models may not need to accurately describe the complex biology of cancer, but to provide a trigger for decision making, often upon binary endpoints. For many years, we have set ourselves the lofty goal of predicting the tumor burden evolution during treatment with ever decreasing error to the actual data [14-16]; yet the clinical endpoint for patients is often not the actual tumor volume dynamics but binary endpoints such as continuous response or cancer progression, tumor control or treatment failure. Machine learning approaches (or simple statistics) can identify threshold values for tumor burden at different time points during therapy that stratify patients into the different outcomes [17-19]. Then, the model purpose becomes to accurately predict whether a tumor will shrink below this threshold or not. A larger error to the data but a correct outcome classification becomes an acceptable tradeoff for better fits but incorrect predictions. With this understanding, we have seen unprecedented model prediction accuracy for individual patients from few response measurements early during therapy [18]. The dilemma is visualized in Figure 1. For both patients, one head and neck cancer patient treated with radiotherapy and one prostate cancer patient treated with intermittent hormone therapy, only a few of the 100 predicted disease trajectories each mimic the eventual clinically observed dynamics. Yet, the majority of the simulations accurately predict disease burden to be above or to be below the learned thresholds for tumor control or treatment resistance.
Modeling efforts support various goals, linked to different expectation as to what modeling provides to a specific project. For the application of mathematical modeling for personalized medicine, further discussions about what models can and cannot contribute are necessary. For predictive modeling, right or wrong may not be how well the predicted disease dynamics based on uncertain parameter combinations mimic the clinically observed responses and their underlying biology, but the interpretation and actionability of model predictions and their uncertainty. While mathematical models may not be right, they do not have to be wrong. Thus, we may just adopt the philosophy of Assistant Director of Operations Domingo “Ding” Chavez, who taught the young Jack Ryan, Jr., in Tom Clancy's Oath of Office to “Don't practice until you get it right. Practice until you don't get it wrong” [20].

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


