Leveraging LIME explainability and Gustafson-Kessel fuzzy clustering for resume grouping and text summarization
IF 7.6
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Over the years a very large number of classification methods have been developed, which are now being referred to as “classical machine learning”. However, a noticeable gap remains in research linking unsupervised learning techniques with explainable artificial intelligence (XAI) methods. In this study, we address this gap by proposing a novel method to enhance the interpretability of unsupervised learning, particularly for textual data. We integrate XAI techniques with the Gustafson-Kessel (GK) fuzzy clustering algorithm to enhance the capture of semantic relationships in text, in particular, resumes for employment. Our approach leverages the light-weight Sentence-BERT model to generate contextual embeddings, that offer a deeper semantic understanding of resume data. These embeddings provide richer representations compared to traditional textual feature extraction methods. Similar resumes are clustered using the GK fuzzy clustering algorithm to identify common patterns across resumes. Subsequently, informative summaries are used for employment purposes, enhancing resume categorization and job matching. The GK algorithm, was chosen over others as it is especially effective at handling complex structures as compared to other clustering methods. In clustering practice, an evaluation of clustering quality is generally performed. In this work, we conduct statistical analysis, ablation studies, and assess performance using various clustering metrics. We also incorporate Local Interpretable Model-Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) to interpret the cluster memberships of individual resumes, thereby enhancing the transparency and trustworthiness of the clustering process. Our approach, when applied correctly, provides potential employers with clear and interpretable insights into how resumes are grouped. We present results on a resume data set that were summarized by our proposed method. The effective and interpretable clustering is shown in comparison with other clustering methods. The outcome is expected to improve the processing efficiency of applicant profiles and is helpful to human resource management.
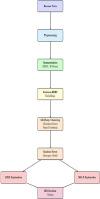
利用LIME可解释性和Gustafson-Kessel模糊聚类进行简历分组和文本摘要
多年来,已经开发了大量的分类方法,这些方法现在被称为“经典机器学习”。然而,在将无监督学习技术与可解释人工智能(XAI)方法联系起来的研究中,仍然存在一个明显的差距。在这项研究中,我们提出了一种新的方法来提高无监督学习的可解释性,特别是对文本数据的可解释性,从而解决了这一差距。我们将XAI技术与Gustafson-Kessel (GK)模糊聚类算法相结合,以增强文本中语义关系的捕获,特别是求职简历。我们的方法利用轻量级的Sentence-BERT模型来生成上下文嵌入,从而对简历数据进行更深层次的语义理解。与传统的文本特征提取方法相比,这些嵌入提供了更丰富的表示。使用GK模糊聚类算法对相似的简历进行聚类,以识别简历之间的共同模式。随后,信息摘要用于就业目的,增强简历分类和工作匹配。之所以选择GK算法,是因为与其他聚类方法相比,它在处理复杂结构方面特别有效。在聚类实践中,通常会对聚类质量进行评估。在这项工作中,我们进行了统计分析,消融研究,并使用各种聚类指标评估性能。我们还引入了局部可解释模型不可知解释(LIME)和SHapley加性解释(SHAP)来解释个人简历的聚类隶属关系,从而提高聚类过程的透明度和可信度。我们的方法,如果应用得当,可以为潜在的雇主提供清晰和可解释的见解,了解简历是如何分组的。我们用我们提出的方法总结了一个简历数据集的结果。通过与其他聚类方法的比较,证明了该聚类方法的有效性和可解释性。该结果有望提高申请人档案的处理效率,并有助于人力资源管理。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Knowledge-Based Systems
工程技术-计算机:人工智能
CiteScore
14.80
自引率
12.50%
发文量
1245
审稿时长
7.8 months
期刊介绍:
Knowledge-Based Systems, an international and interdisciplinary journal in artificial intelligence, publishes original, innovative, and creative research results in the field. It focuses on knowledge-based and other artificial intelligence techniques-based systems. The journal aims to support human prediction and decision-making through data science and computation techniques, provide a balanced coverage of theory and practical study, and encourage the development and implementation of knowledge-based intelligence models, methods, systems, and software tools. Applications in business, government, education, engineering, and healthcare are emphasized.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


