{"title":"Differentiating post-stroke patients from healthy individuals via vision-based skeleton-optical fusion.","authors":"Xiao Han, Ziyan Wang, Liping Li, Kongfa Hu","doi":"10.1186/s12984-025-01726-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>At present, the analysis of abnormal gait in post-stroke patients predominantly relies on wearable devices. However, with the advancements in computer vision technology, the integration of deep learning algorithms has introduced new possibilities for research. In particular, multi-modal fusion technology can effectively combine various modalities obtained through vision-based approaches, enabling more comprehensive and accurate representation of abnormal gait information in post-stroke patients.</p><p><strong>Methods: </strong>The study recruited 70 post-stroke patients and 70 healthy individuals to capture video recordings of their gait. We used Human Pose Estimation (HPE) to extract skeleton points from each frame and computed the optical flow information of these points and the corresponding angular variations of the lower limbs. Additionally, depth space features were extracted using ResNet-50 and subsequently integrated. For classification, a Long Short-Term Memory (LSTM) network was employed to analyze the fused features.</p><p><strong>Results: </strong>To evaluate the effectiveness of the feature extraction method, we tested it on both an open dataset and a self-collected clinical dataset, comparing it with CNN-RNN and Vision Transformer (ViT). The results from the LSTM network, after inputting the fused features, demonstrated optimal performance with 2 layers and 128 hidden units, achieving accuracies of 0.8794±0.0447 and 0.8778±0.0347, respectively.</p><p><strong>Conclusion: </strong>It was found that optical flow information calculated based on skeleton points, combined with variations in knee flexion and ankle dorsiflexion angles, improved the interpretability of the analytical framework. This improvement enables clinicians to gain a clearer understanding of the model's decision-making process, thereby increasing their confidence in its outputs. By employing a multi-modal fusion approach, information from different modalities is integrated, which not only broadens the analytical perspectives but also facilitates clinicians' deeper insights into the patient's gait characteristics.</p>","PeriodicalId":16384,"journal":{"name":"Journal of NeuroEngineering and Rehabilitation","volume":"22 1","pages":"209"},"PeriodicalIF":5.2000,"publicationDate":"2025-10-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12509394/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of NeuroEngineering and Rehabilitation","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s12984-025-01726-5","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
Abstract
Background: At present, the analysis of abnormal gait in post-stroke patients predominantly relies on wearable devices. However, with the advancements in computer vision technology, the integration of deep learning algorithms has introduced new possibilities for research. In particular, multi-modal fusion technology can effectively combine various modalities obtained through vision-based approaches, enabling more comprehensive and accurate representation of abnormal gait information in post-stroke patients.
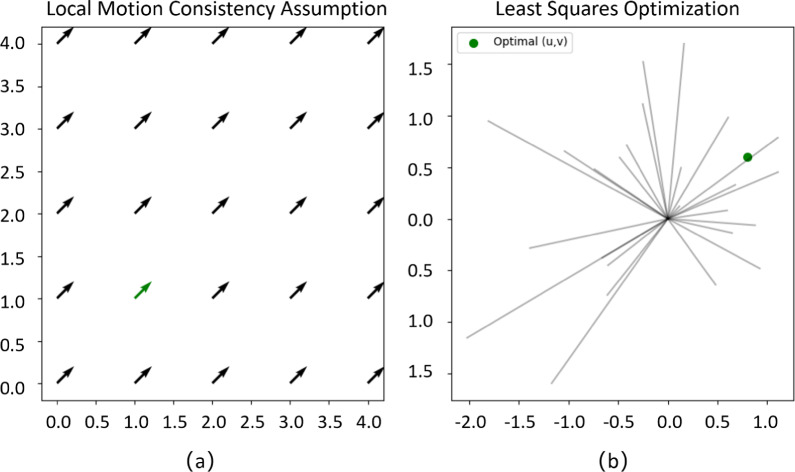
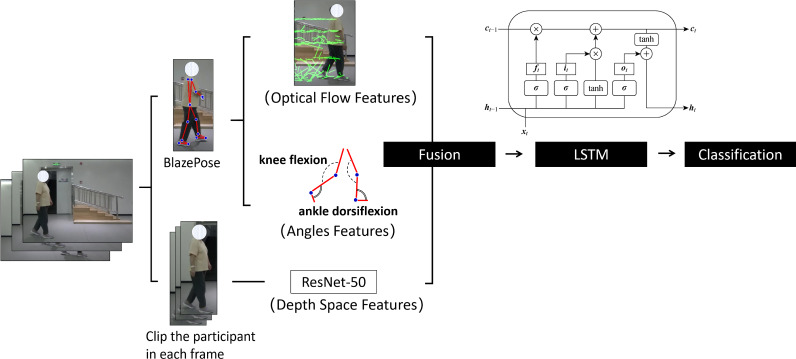
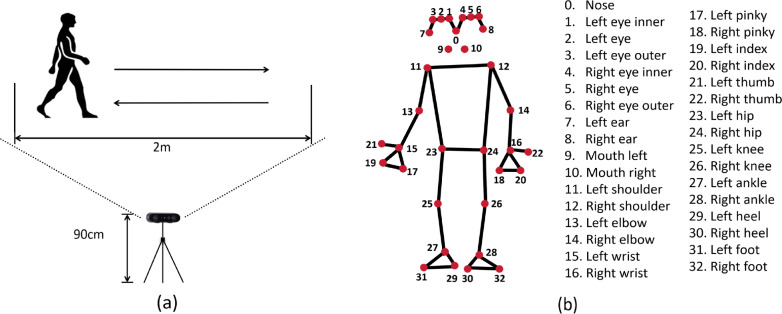
Methods: The study recruited 70 post-stroke patients and 70 healthy individuals to capture video recordings of their gait. We used Human Pose Estimation (HPE) to extract skeleton points from each frame and computed the optical flow information of these points and the corresponding angular variations of the lower limbs. Additionally, depth space features were extracted using ResNet-50 and subsequently integrated. For classification, a Long Short-Term Memory (LSTM) network was employed to analyze the fused features.
Results: To evaluate the effectiveness of the feature extraction method, we tested it on both an open dataset and a self-collected clinical dataset, comparing it with CNN-RNN and Vision Transformer (ViT). The results from the LSTM network, after inputting the fused features, demonstrated optimal performance with 2 layers and 128 hidden units, achieving accuracies of 0.8794±0.0447 and 0.8778±0.0347, respectively.
Conclusion: It was found that optical flow information calculated based on skeleton points, combined with variations in knee flexion and ankle dorsiflexion angles, improved the interpretability of the analytical framework. This improvement enables clinicians to gain a clearer understanding of the model's decision-making process, thereby increasing their confidence in its outputs. By employing a multi-modal fusion approach, information from different modalities is integrated, which not only broadens the analytical perspectives but also facilitates clinicians' deeper insights into the patient's gait characteristics.
期刊介绍:
Journal of NeuroEngineering and Rehabilitation considers manuscripts on all aspects of research that result from cross-fertilization of the fields of neuroscience, biomedical engineering, and physical medicine & rehabilitation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


