Baptiste Bauvin, Thibaud Godon, Guillaume Bachelot, Claudia Carpentier, Riikka Huusaari, Maxime Deraspe, Juho Rousu, Caroline Quach, Jacques Corbeil
{"title":"Extracting a COVID-19 signature from a multi-omic dataset.","authors":"Baptiste Bauvin, Thibaud Godon, Guillaume Bachelot, Claudia Carpentier, Riikka Huusaari, Maxime Deraspe, Juho Rousu, Caroline Quach, Jacques Corbeil","doi":"10.3389/fbinf.2025.1645785","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>The complexity of COVID-19 requires approaches that extend beyond symptom-based descriptors. Multi-omic data, combining clinical, proteomic, and metabolomic information, offer a more detailed view of disease mechanisms and biomarker discovery.</p><p><strong>Methods: </strong>As part of a large-scale Quebec initiative, we collected extensive datasets from COVID-19 positive and negative patient samples. Using a multi-view machine learning framework with ensemble methods, we integrated thousands of features across clinical, proteomic, and metabolomic domains to classify COVID-19 status. We further applied a novel feature relevance methodology to identify condensed signatures.</p><p><strong>Results: </strong>Our models achieved a balanced accuracy of 89% ± 5% despite the high-dimensional nature of the data. Feature selection yielded 12- and 50-feature signatures that improved classification accuracy by at least 3% compared to the full feature set. These signatures were both accurate and interpretable.</p><p><strong>Discussion: </strong>This work demonstrates that multi-omic integration, combined with advanced machine learning, enables the extraction of robust COVID-19 signatures from complex datasets. The condensed biomarker sets provide a practical path toward improved diagnosis and precision medicine, representing a significant advancement in COVID-19 biomarker discovery.</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":"5 ","pages":"1645785"},"PeriodicalIF":3.9000,"publicationDate":"2025-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12497780/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2025.1645785","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: The complexity of COVID-19 requires approaches that extend beyond symptom-based descriptors. Multi-omic data, combining clinical, proteomic, and metabolomic information, offer a more detailed view of disease mechanisms and biomarker discovery.
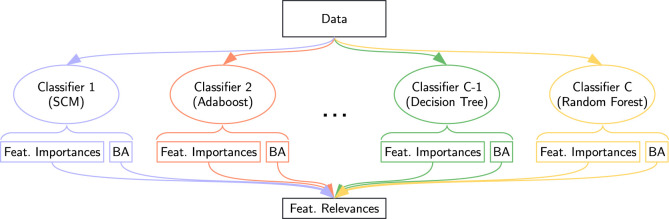
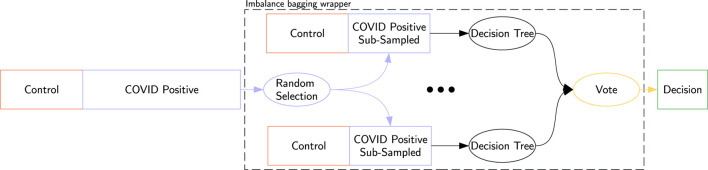
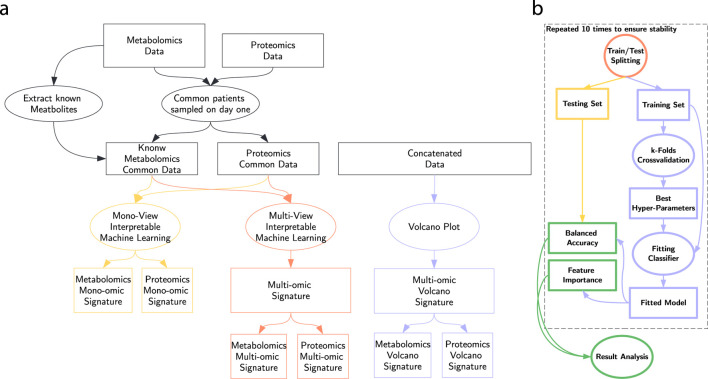
Methods: As part of a large-scale Quebec initiative, we collected extensive datasets from COVID-19 positive and negative patient samples. Using a multi-view machine learning framework with ensemble methods, we integrated thousands of features across clinical, proteomic, and metabolomic domains to classify COVID-19 status. We further applied a novel feature relevance methodology to identify condensed signatures.
Results: Our models achieved a balanced accuracy of 89% ± 5% despite the high-dimensional nature of the data. Feature selection yielded 12- and 50-feature signatures that improved classification accuracy by at least 3% compared to the full feature set. These signatures were both accurate and interpretable.
Discussion: This work demonstrates that multi-omic integration, combined with advanced machine learning, enables the extraction of robust COVID-19 signatures from complex datasets. The condensed biomarker sets provide a practical path toward improved diagnosis and precision medicine, representing a significant advancement in COVID-19 biomarker discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


