{"title":"Decoding non-linearity and complexity: deep tabular learning approaches for materials science","authors":"Vahid Attari and Raymundo Arroyave","doi":"10.1039/D5DD00166H","DOIUrl":null,"url":null,"abstract":"<p >Materials datasets, particularly those capturing high-temperature properties pose significant challenges for learning tasks due to their skewed distributions, wide feature ranges, and multimodal behaviors. While tree-based models like XGBoost are inherently non-linear and often perform well on many tabular problems, their reliance on piecewise constant splits can limit effectiveness when modeling smooth, long-tailed, or higher-order relationships prevalent in advanced materials data. To address these challenges, we investigate the effectiveness of encoder–decoder model for data transformation using regularized Fully Dense Networks (FDN-R), Disjunctive Normal Form Networks (DNF-Net), 1D Convolutional Neural Networks (CNNs), and Variational Autoencoders, along with TabNet, a hybrid attention-based model, to address these challenges. Our results indicate that while XGBoost remains competitive on simpler tasks, encoder–decoder models, particularly those based on regularized FDN-R and DNF-Net, demonstrate better generalization on highly skewed targets like creep resistance, across small, medium, and large datasets. TabNet's attention mechanism offers moderate gains but underperforms on extreme values. These findings emphasize the importance of aligning model architecture with feature complexity and demonstrate the promise of hybrid encoder–decoder models for robust and generalizable materials prediction from composition data.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 10","pages":" 2765-2780"},"PeriodicalIF":6.2000,"publicationDate":"2025-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2025/dd/d5dd00166h?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2025/dd/d5dd00166h","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
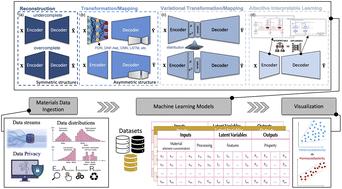
Materials datasets, particularly those capturing high-temperature properties pose significant challenges for learning tasks due to their skewed distributions, wide feature ranges, and multimodal behaviors. While tree-based models like XGBoost are inherently non-linear and often perform well on many tabular problems, their reliance on piecewise constant splits can limit effectiveness when modeling smooth, long-tailed, or higher-order relationships prevalent in advanced materials data. To address these challenges, we investigate the effectiveness of encoder–decoder model for data transformation using regularized Fully Dense Networks (FDN-R), Disjunctive Normal Form Networks (DNF-Net), 1D Convolutional Neural Networks (CNNs), and Variational Autoencoders, along with TabNet, a hybrid attention-based model, to address these challenges. Our results indicate that while XGBoost remains competitive on simpler tasks, encoder–decoder models, particularly those based on regularized FDN-R and DNF-Net, demonstrate better generalization on highly skewed targets like creep resistance, across small, medium, and large datasets. TabNet's attention mechanism offers moderate gains but underperforms on extreme values. These findings emphasize the importance of aligning model architecture with feature complexity and demonstrate the promise of hybrid encoder–decoder models for robust and generalizable materials prediction from composition data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


