Fall detection using deep learning with features computed from recursive quadratic splits of video frames
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
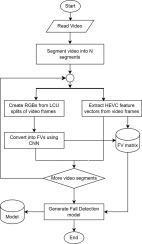
Accidental falls are a leading cause of injury and death worldwide, particularly among the elderly. Despite extensive research on fall detection, many existing systems remain limited by reliance on wearable sensors that are inconvenient for continuous use, or vision-based approaches that require full video decoding, human pose estimation, or simplified datasets that fail to capture the complexity of real-life environments. As a result, their accuracy often deteriorates in realistic scenarios such as nursing homes or crowded public spaces. In this paper, we introduce a novel fall detection framework that leverages information embedded in the High Efficiency Video Coding (HEVC) standard. Unlike traditional vision-based methods, our approach extracts spatio-temporal features directly from recursive block splits and other HEVC coding information. This includes creating a sequence of four RGB input images which capture block sizes and splits of the video frames in a visual manner. The block sizes in video coding are determined based on the spatio-temporal activities in the frames, hence the suitability of using them as features. Other features are also derived from the coded videos, including compression modes, motion vectors, and prediction residuals. To enhance robustness, we integrate these features into deep learning models and employ fusion strategies that combine complementary representations. Extensive evaluations on two challenging datasets: the Real-World Fall Dataset (RFDS) and the High-Quality Fall Simulation Dataset (HQFSD), demonstrate that our method achieves superior accuracy and robustness compared to prior work. In addition, our method requires only around 23 GFLOPs per video because the deep learning network is executed on just four fixed-frame representations, whereas traditional pipelines process every frame individually, often amounting to hundreds of frames per video and orders of magnitude higher FLOPs.
使用深度学习的跌倒检测,从视频帧的递归二次分割中计算特征
意外跌倒是全世界,尤其是老年人受伤和死亡的主要原因。尽管对跌倒检测进行了广泛的研究,但许多现有系统仍然受限于可穿戴传感器,这些传感器不便于连续使用,或者基于视觉的方法需要完整的视频解码、人体姿势估计或简化的数据集,这些方法无法捕捉现实环境的复杂性。因此,在养老院或拥挤的公共场所等现实场景中,它们的准确性往往会下降。在本文中,我们介绍了一种新的跌倒检测框架,该框架利用了高效视频编码(HEVC)标准中嵌入的信息。与传统的基于视觉的方法不同,我们的方法直接从递归块分割和其他HEVC编码信息中提取时空特征。这包括创建一个由四个RGB输入图像组成的序列,以视觉方式捕获块大小和视频帧的分割。视频编码中的块大小是根据帧中的时空活动来确定的,因此将它们作为特征是合适的。其他特征也从编码视频中得到,包括压缩模式,运动矢量和预测残差。为了增强鲁棒性,我们将这些特征集成到深度学习模型中,并采用结合互补表示的融合策略。对两个具有挑战性的数据集:真实世界秋季数据集(RFDS)和高质量秋季模拟数据集(HQFSD)的广泛评估表明,与之前的工作相比,我们的方法具有更高的准确性和鲁棒性。此外,我们的方法每个视频只需要大约23 GFLOPs,因为深度学习网络只在四个固定帧表示上执行,而传统的流水线单独处理每帧,通常每个视频达到数百帧,FLOPs更高。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


