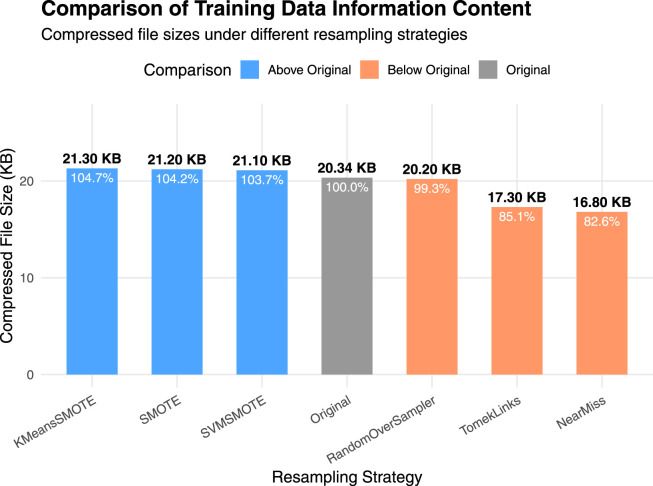
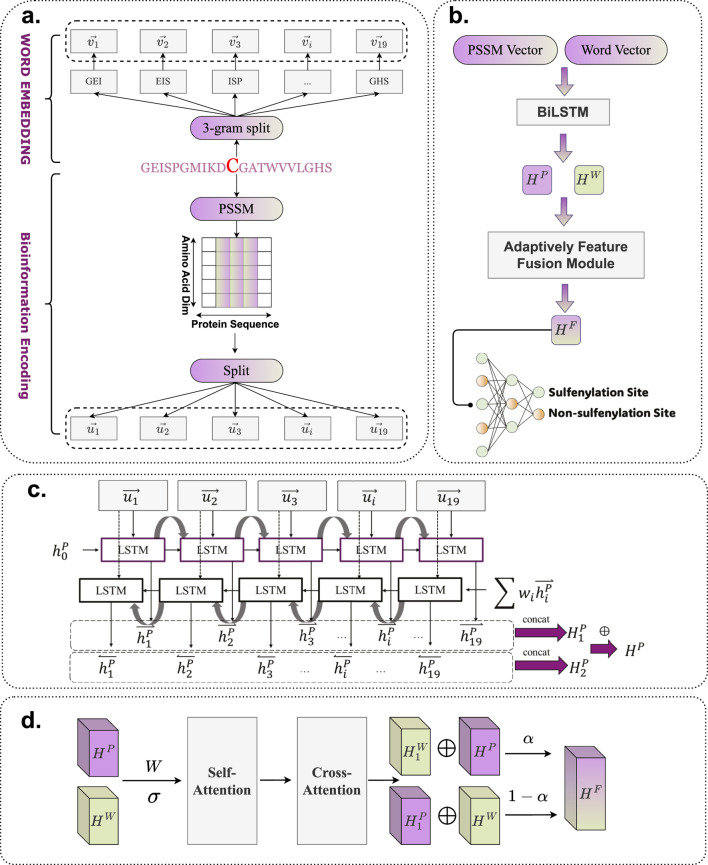
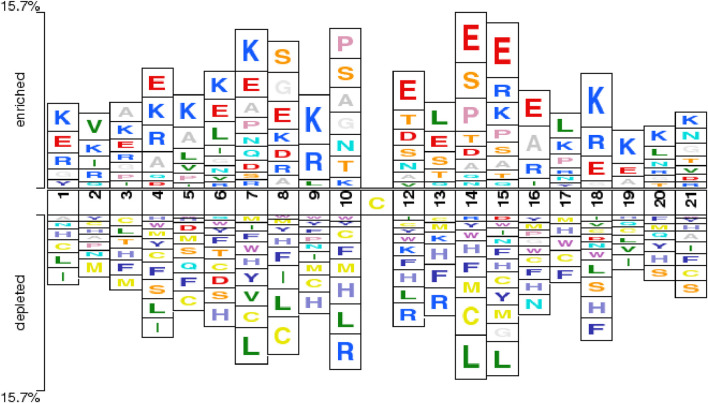
{"title":"BioSemAF-BiLSTM: a protein sequence feature extraction framework based on semantic and evolutionary information.","authors":"Zihan Zhang, Yixuan Wang","doi":"10.3389/fgene.2025.1616880","DOIUrl":null,"url":null,"abstract":"<p><p>S-sulfenylation is a critical post-translational modification that plays an important role in regulating protein function, redox signaling, and maintaining cellular homeostasis. Accurate identification of S-sulfenylation sites is essential for understanding its biological significance and relevance to disease. However, the exclusive detection of S-sulfenylation sites through experimental methods remains challenging, as these approaches are often time-consuming and costly. Motivated by this issue, the present work proposed a deep learning-based computational framework, named BioSemAF-BiLSTM, which integrated evolutionary and semantic features to improve the prediction performance of S-sulfenylation sites. The framework employed fastText to generate subword-based sequence embeddings that captured local contextual information, and employed position-specific scoring matrices (PSSMs) to extract evolutionary conservation features. Importantly, we also quantitatively evaluated feature sufficiency at the protein sequence level using a sequence compression-based measure approximating Kolmogorov complexity, revealing an 11% information loss rate in predictive modeling using these features. These representations were subsequently fed into a bidirectional long short-term memory (BiLSTM) network to model long-range dependencies, and were further refined via an adaptive feature fusion module to enhance feature interaction. Experimental results on a benchmark dataset demonstrated that the model significantly outperformed conventional machine learning methods and current state-of-the-art deep learning approaches, achieving an accuracy of 89.32% on an independent test. It demonstrated improved sensitivity and specificity, effectively bridging the gap between bioinformatics and deep learning, and offered a robust computational tool for predicting post-translational modification sites.</p>","PeriodicalId":12750,"journal":{"name":"Frontiers in Genetics","volume":"16 ","pages":"1616880"},"PeriodicalIF":2.8000,"publicationDate":"2025-09-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12483914/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Genetics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.3389/fgene.2025.1616880","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
S-sulfenylation is a critical post-translational modification that plays an important role in regulating protein function, redox signaling, and maintaining cellular homeostasis. Accurate identification of S-sulfenylation sites is essential for understanding its biological significance and relevance to disease. However, the exclusive detection of S-sulfenylation sites through experimental methods remains challenging, as these approaches are often time-consuming and costly. Motivated by this issue, the present work proposed a deep learning-based computational framework, named BioSemAF-BiLSTM, which integrated evolutionary and semantic features to improve the prediction performance of S-sulfenylation sites. The framework employed fastText to generate subword-based sequence embeddings that captured local contextual information, and employed position-specific scoring matrices (PSSMs) to extract evolutionary conservation features. Importantly, we also quantitatively evaluated feature sufficiency at the protein sequence level using a sequence compression-based measure approximating Kolmogorov complexity, revealing an 11% information loss rate in predictive modeling using these features. These representations were subsequently fed into a bidirectional long short-term memory (BiLSTM) network to model long-range dependencies, and were further refined via an adaptive feature fusion module to enhance feature interaction. Experimental results on a benchmark dataset demonstrated that the model significantly outperformed conventional machine learning methods and current state-of-the-art deep learning approaches, achieving an accuracy of 89.32% on an independent test. It demonstrated improved sensitivity and specificity, effectively bridging the gap between bioinformatics and deep learning, and offered a robust computational tool for predicting post-translational modification sites.
s -磺酰化是一种重要的翻译后修饰,在调节蛋白质功能、氧化还原信号传导和维持细胞稳态方面发挥重要作用。准确识别s -亚砜化位点对于理解其生物学意义和与疾病的相关性至关重要。然而,通过实验方法单独检测s -亚砜化位点仍然具有挑战性,因为这些方法通常既耗时又昂贵。基于这一问题,本研究提出了一种基于深度学习的计算框架BioSemAF-BiLSTM,该框架集成了进化和语义特征,以提高s -亚砜化位点的预测性能。该框架使用fastText生成基于子词的序列嵌入,捕获局部上下文信息,并使用位置特定评分矩阵(PSSMs)提取进化守恒特征。重要的是,我们还在蛋白质序列水平上使用基于序列压缩的近似Kolmogorov复杂度的度量定量评估了特征充分性,揭示了使用这些特征进行预测建模的信息损失率为11%。这些表征随后被输入双向长短期记忆(BiLSTM)网络来建模长期依赖,并通过自适应特征融合模块进一步细化以增强特征交互。在基准数据集上的实验结果表明,该模型明显优于传统的机器学习方法和当前最先进的深度学习方法,在独立测试中达到了89.32%的准确率。它显示出更高的灵敏度和特异性,有效地弥合了生物信息学和深度学习之间的差距,并为预测翻译后修饰位点提供了一个强大的计算工具。
Frontiers in GeneticsBiochemistry, Genetics and Molecular Biology-Molecular Medicine
CiteScore
5.50
自引率
8.10%
发文量
3491
审稿时长
14 weeks
期刊介绍:
Frontiers in Genetics publishes rigorously peer-reviewed research on genes and genomes relating to all the domains of life, from humans to plants to livestock and other model organisms. Led by an outstanding Editorial Board of the world’s leading experts, this multidisciplinary, open-access journal is at the forefront of communicating cutting-edge research to researchers, academics, clinicians, policy makers and the public.
The study of inheritance and the impact of the genome on various biological processes is well documented. However, the majority of discoveries are still to come. A new era is seeing major developments in the function and variability of the genome, the use of genetic and genomic tools and the analysis of the genetic basis of various biological phenomena.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


