Xufei Luo, Zeming Li, Zhenhua Yang, Bingyi Wang, Yanfang Ma, Fengxian Chen, Qi Wang, Long Ge, James Zou, Lu Zhang, Yaolong Chen, Zhaoxiang Bian
{"title":"Using Large Language Models to Assess the Consistency of Randomized Controlled Trials on AI Interventions With CONSORT-AI: Cross-Sectional Survey.","authors":"Xufei Luo, Zeming Li, Zhenhua Yang, Bingyi Wang, Yanfang Ma, Fengxian Chen, Qi Wang, Long Ge, James Zou, Lu Zhang, Yaolong Chen, Zhaoxiang Bian","doi":"10.2196/72412","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Chatbots based on large language models (LLMs) have shown promise in evaluating the consistency of research. Previously, researchers used LLM to assess if randomized controlled trial (RCT) abstracts adhered to the CONSORT-Abstract guidelines. However, the consistency of artificial intelligence (AI) interventional RCTs aligning with the CONSORT-AI (Consolidated Standards of Reporting Trials-Artificial Intelligence) standards by LLMs remains unclear.</p><p><strong>Objective: </strong>The aim of this study is to identify the consistency of RCTs on AI interventions with CONSORT-AI using chatbots based on LLMs.</p><p><strong>Methods: </strong>This cross-sectional study employed 6 LLM models to assess the consistency of RCTs on AI interventions. The sample selection is based on articles published in JAMA Network Open, which included a total of 41 RCTs. All queries were submitted to LLMs through an application programming interface with a temperature setting of 0 to ensure deterministic responses. One researcher posed the questions to each model, while another independently verified the responses for validity before recording the results. The Overall Consistency Score (OCS), recall, inter-rater reliability, and consistency of contents were analyzed.</p><p><strong>Results: </strong>We found gpt-4-0125-preview has the best average OCS on the basis of the results obtained by JAMA Network Open authors and by us (86.5%, 95% CI 82.5%-90.5% and 81.6%, 95% CI 77.6%-85.6%, respectively), followed by gpt-4-1106-preview (80.3%, 95% CI 76.3%-84.3% and 78.0%, 95% CI 74.0%-82.0%, respectively). The model with the worst average OCS is gpt-3.5-turbo-0125 on the basis of the results obtained by JAMA Network Open authors and by us (61.9%, 95% CI 57.9%-65.9% and 63.0%, 95% CI 59.0%-67.0%, respectively). Among the 11 unique items of CONSORT-AI, Item 2 (\"State the inclusion and exclusion criteria at the level of the input data\") received the poorest overall evaluation across the 6 models, with an average OCS of 48.8%. For other items, those with an average OCS greater than 80% across the 6 models included Items 1, 5, 8, and 9.</p><p><strong>Conclusions: </strong>GPT-4 variants demonstrate strong performance in assessing the consistency of RCTs with CONSORT-AI. Nonetheless, refining the prompts could enhance the precision and consistency of the outcomes. While AI tools like GPT-4 variants are valuable, they are not yet fully autonomous in addressing complex and nuanced tasks such as adherence to CONSORT-AI standards. Therefore, integrating AI with higher levels of human supervision and expertise will be crucial to ensuring more reliable and efficient evaluations, ultimately advancing the quality of medical research.</p>","PeriodicalId":16337,"journal":{"name":"Journal of Medical Internet Research","volume":"27 ","pages":"e72412"},"PeriodicalIF":6.0000,"publicationDate":"2025-09-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12466798/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Internet Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/72412","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Chatbots based on large language models (LLMs) have shown promise in evaluating the consistency of research. Previously, researchers used LLM to assess if randomized controlled trial (RCT) abstracts adhered to the CONSORT-Abstract guidelines. However, the consistency of artificial intelligence (AI) interventional RCTs aligning with the CONSORT-AI (Consolidated Standards of Reporting Trials-Artificial Intelligence) standards by LLMs remains unclear.
Objective: The aim of this study is to identify the consistency of RCTs on AI interventions with CONSORT-AI using chatbots based on LLMs.
Methods: This cross-sectional study employed 6 LLM models to assess the consistency of RCTs on AI interventions. The sample selection is based on articles published in JAMA Network Open, which included a total of 41 RCTs. All queries were submitted to LLMs through an application programming interface with a temperature setting of 0 to ensure deterministic responses. One researcher posed the questions to each model, while another independently verified the responses for validity before recording the results. The Overall Consistency Score (OCS), recall, inter-rater reliability, and consistency of contents were analyzed.
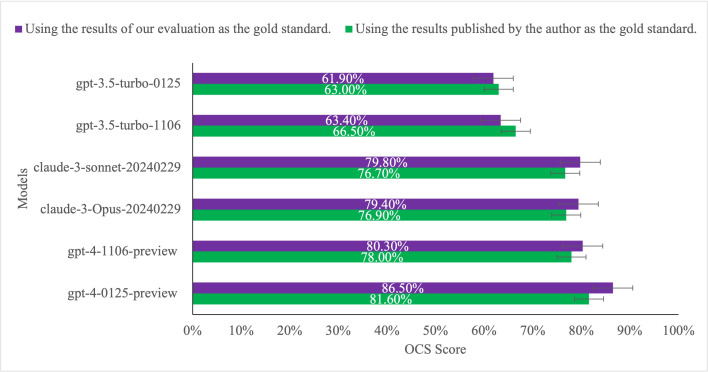
Results: We found gpt-4-0125-preview has the best average OCS on the basis of the results obtained by JAMA Network Open authors and by us (86.5%, 95% CI 82.5%-90.5% and 81.6%, 95% CI 77.6%-85.6%, respectively), followed by gpt-4-1106-preview (80.3%, 95% CI 76.3%-84.3% and 78.0%, 95% CI 74.0%-82.0%, respectively). The model with the worst average OCS is gpt-3.5-turbo-0125 on the basis of the results obtained by JAMA Network Open authors and by us (61.9%, 95% CI 57.9%-65.9% and 63.0%, 95% CI 59.0%-67.0%, respectively). Among the 11 unique items of CONSORT-AI, Item 2 ("State the inclusion and exclusion criteria at the level of the input data") received the poorest overall evaluation across the 6 models, with an average OCS of 48.8%. For other items, those with an average OCS greater than 80% across the 6 models included Items 1, 5, 8, and 9.
Conclusions: GPT-4 variants demonstrate strong performance in assessing the consistency of RCTs with CONSORT-AI. Nonetheless, refining the prompts could enhance the precision and consistency of the outcomes. While AI tools like GPT-4 variants are valuable, they are not yet fully autonomous in addressing complex and nuanced tasks such as adherence to CONSORT-AI standards. Therefore, integrating AI with higher levels of human supervision and expertise will be crucial to ensuring more reliable and efficient evaluations, ultimately advancing the quality of medical research.
背景:基于大型语言模型(llm)的聊天机器人在评估研究的一致性方面显示出前景。以前,研究人员使用LLM来评估随机对照试验(RCT)摘要是否遵守了conber - abstract指南。然而,人工智能(AI)干预性随机对照试验与法学硕士的conber -AI(人工智能综合报告试验标准)标准的一致性仍不清楚。目的:本研究的目的是确定基于llm的聊天机器人的人工智能干预与concur -AI的随机对照试验的一致性。方法:本横断面研究采用6个LLM模型评估人工智能干预的随机对照试验的一致性。样本选择基于发表在JAMA Network Open上的文章,共包括41项随机对照试验。所有查询都通过温度设置为0的应用程序编程接口提交给llm,以确保确定性响应。一名研究人员向每个模型提出问题,而另一名研究人员在记录结果之前独立验证回答的有效性。对总体一致性评分(OCS)、召回率、评分者间信度和内容一致性进行分析。结果:根据JAMA Network Open作者和我们获得的结果,我们发现gpt-4-0125-preview具有最佳的平均OCS(分别为86.5%,95% CI 82.5%-90.5%和81.6%,95% CI 77.6%-85.6%),其次是gpt-4-1106-preview(分别为80.3%,95% CI 76.3%-84.3%和78.0%,95% CI 74.0%-82.0%)。根据JAMA Network Open作者和我们获得的结果,平均OCS最差的模型是gpt-3.5-turbo-0125(分别为61.9%,95% CI 57.9%-65.9%和63.0%,95% CI 59.0%-67.0%)。在concont - ai的11个独特项目中,项目2(“在输入数据的层面上陈述纳入和排除标准”)在6个模型中获得了最差的综合评价,平均OCS为48.8%。对于其他项目,6个模型中平均OCS大于80%的项目包括项目1、5、8和9。结论:GPT-4变体在评估rct与concur - ai的一致性方面表现出很强的性能。尽管如此,改进提示可以提高结果的准确性和一致性。虽然像GPT-4变体这样的人工智能工具很有价值,但它们在解决复杂而微妙的任务(如遵守congo -AI标准)方面还不能完全自主。因此,将人工智能与更高水平的人类监督和专业知识相结合,对于确保更可靠、更有效的评估,最终提高医学研究的质量至关重要。
期刊介绍:
The Journal of Medical Internet Research (JMIR) is a highly respected publication in the field of health informatics and health services. With a founding date in 1999, JMIR has been a pioneer in the field for over two decades.
As a leader in the industry, the journal focuses on digital health, data science, health informatics, and emerging technologies for health, medicine, and biomedical research. It is recognized as a top publication in these disciplines, ranking in the first quartile (Q1) by Impact Factor.
Notably, JMIR holds the prestigious position of being ranked #1 on Google Scholar within the "Medical Informatics" discipline.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


