Leveraging few-shot learning and large language models for analyzing blood pressure variations across biological sex from scientific literature
IF 6.3
2区 医学
Q1 BIOLOGY
引用次数: 0
Abstract
Background:
Current blood pressure (BP) technologies and standards were established decades ago, and these standards are still used worldwide today, often without adjusting BP readings for individual demographic factors such as sex and age. While these standards provide useful guidelines and help identify at-risk patients, they are not fully reliable for diagnosis due to the lack of demographic considerations. This study aims to assess the feasibility of using large language models (LLMs) for the automated extraction of BP-related information from the scientific literature, with a focus on biological sex-based distinctions in BP distributions.
Method:
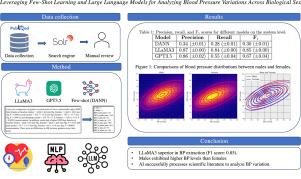
We employed natural language processing (NLP) methods to extract the means and standard deviations of BP values from the literature, distinguishing by biological sex. We developed a Solr-based search engine to retrieve scientific articles containing BP-related keywords and biological sex indicators from PubMed. From the retrieved articles, we created a manually reviewed subset comprising 213 articles including 90 cases that reported BP values based on biological sex. We experimented with one few-shot learning method and two zero-shot LLM-based methods—LLaMA3 and GPT-3.5—to extract the mean and standard deviations of BP values, and the associated biological sex. Based on the automatically-extracted information, we generated heatmaps and contour plots to study the variations of BP values across biological sex.
Results:
The inter-annotator agreement (IAA) between the two annotators measured using Cohen’s kappa (McHugh, 2012) was 0.74. The best performing system was LLaMA3 with an F1 score of 0.85 (0.00). The few-shot learning method (DANN) exhibited low performance with an average F1 score of 0.30 (0.01). GPT-3.5 achieved moderate performance with an average F1 score of 0.67 (0.04). The contour plots show that males tend to exhibit higher BP values than females.
Conclusions:
Our results demonstrate that LLMs can be reliable in extracting population-level BP and biological sex information from clinical literature. They also outperform traditional low-shot information extraction systems in this context, showcasing their ability to extract BP-related information more accurately and efficiently. By employing LLMs, we provide a scalable framework for analyzing demographic differences in BP and emphasize the broader utility of LLMs in addressing similar challenges in biomedical research.
利用几次学习和大型语言模型,从科学文献中分析不同生物性别的血压变化
背景:目前的血压(BP)技术和标准是在几十年前建立的,这些标准今天仍在世界范围内使用,通常没有根据性别和年龄等个人人口因素调整血压读数。虽然这些标准提供了有用的指导方针,并有助于识别高危患者,但由于缺乏人口统计学方面的考虑,它们在诊断方面并不完全可靠。本研究旨在评估使用大型语言模型(LLMs)从科学文献中自动提取BP相关信息的可行性,重点研究BP分布中基于生物性别的差异。方法:采用自然语言处理(NLP)方法从文献中提取BP值的均值和标准差,并按生物性别进行区分。我们开发了一个基于solr的搜索引擎,从PubMed中检索包含bp相关关键词和生物性别指标的科学文章。从检索到的文章中,我们创建了一个由213篇文章组成的人工审查子集,其中包括90例基于生物性别报告的BP值。我们使用一种少次学习方法和两种零次学习方法(llama3和gpt -3.5)来提取BP值的均值和标准差以及相关的生物性别。基于自动提取的信息,我们生成了热图和等高线图来研究BP值在生物性别之间的变化。结果:使用Cohen’s kappa (McHugh, 2012)测量的两个注释者间的注释者间一致性(IAA)为0.74。表现最好的体系为LLaMA3, F1评分为0.85(±0.00)。少镜头学习法(DANN)表现较差,平均F1分数为0.30(±0.01)。GPT-3.5表现中等,平均F1评分为0.67(±0.04)。等高线图显示,雄性的BP值高于雌性。结论:我们的研究结果表明,LLMs可以可靠地从临床文献中提取人群水平的血压和生物性别信息。在这种情况下,它们也优于传统的低射击信息提取系统,展示了它们更准确、更有效地提取bp相关信息的能力。通过使用法学硕士,我们提供了一个可扩展的框架来分析英国石油公司的人口统计学差异,并强调法学硕士在解决生物医学研究中类似挑战方面的更广泛效用。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computers in biology and medicine
工程技术-工程:生物医学
CiteScore
11.70
自引率
10.40%
发文量
1086
审稿时长
74 days
期刊介绍:
Computers in Biology and Medicine is an international forum for sharing groundbreaking advancements in the use of computers in bioscience and medicine. This journal serves as a medium for communicating essential research, instruction, ideas, and information regarding the rapidly evolving field of computer applications in these domains. By encouraging the exchange of knowledge, we aim to facilitate progress and innovation in the utilization of computers in biology and medicine.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


