Samar Binkheder, Xiaofu Liu, Michael Wu, Lei Wang, Aditi Shendre, Sara K Quinney, Wei-Qi Wei, Lang Li
{"title":"Biomedical literature-based clinical phenotype definition discovery using large language models.","authors":"Samar Binkheder, Xiaofu Liu, Michael Wu, Lei Wang, Aditi Shendre, Sara K Quinney, Wei-Qi Wei, Lang Li","doi":"10.1093/database/baaf047","DOIUrl":null,"url":null,"abstract":"<p><p>Electronic health record (EHR) phenotyping is a high-demand task because most phenotypes are not usually readily defined. The objective of this study is to develop an effective text-mining approach that automatically extracts clinical phenotype definitions-related sentences from biomedical literature. Abstract-level and full-text sentence-level classifiers were developed for clinical phenotype discovery from PubMed. We compared the performance of the abstract-level classifier on machine learning algorithms: support vector machine (SVM), logistic regression (LR), naïve Bayes, and decision tree. SVM classifier showed the best performance (F-measure = 98%) in identifying clinical phenotype-relevant abstracts. It predicted 459 406 clinical phenotype-related abstracts. For the full-text sentence-level classifier, we compared the performance of SVM, LR, naïve Bayes, decision trees, convolutional neural networks, Bidirectional Encoder Representations from Transformers (BERT), and Bidirectional Encoder Representations from Transformers for Biomedical Text Mining (BioBERT). BioBERT model was the best performer among the full-text sentence-level classifiers (F-measure = 91%). We used these two optimal classifiers for large-scale screening of the PubMed database, starting with abstract retrieval and followed by predicting clinical phenotype-related sentences from full texts. The large-scale screening predicted over two million clinical phenotype-related sentences. Lastly, we developed a knowledgebase using positively predicted sentences, allowing users to query clinical phenotype-related sentences with a phenotype term of interest. The Clinical Phenotype Knowledgebase (CliPheKB) enables users to search for clinical phenotype terms and retrieve sentences related to a specific clinical phenotype of interest (https://cliphekb.shinyapps.io/phenotype-main/). Building upon prior methods, we developed a text mining pipeline to automatically extract clinical phenotype definition-related sentences from the literature. This high-throughput phenotyping approach is generalizable and scalable, and it is complementary to existing EHR phenotyping methods.</p>","PeriodicalId":10923,"journal":{"name":"Database: The Journal of Biological Databases and Curation","volume":"2025 ","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2025-01-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12462612/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Database: The Journal of Biological Databases and Curation","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/database/baaf047","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
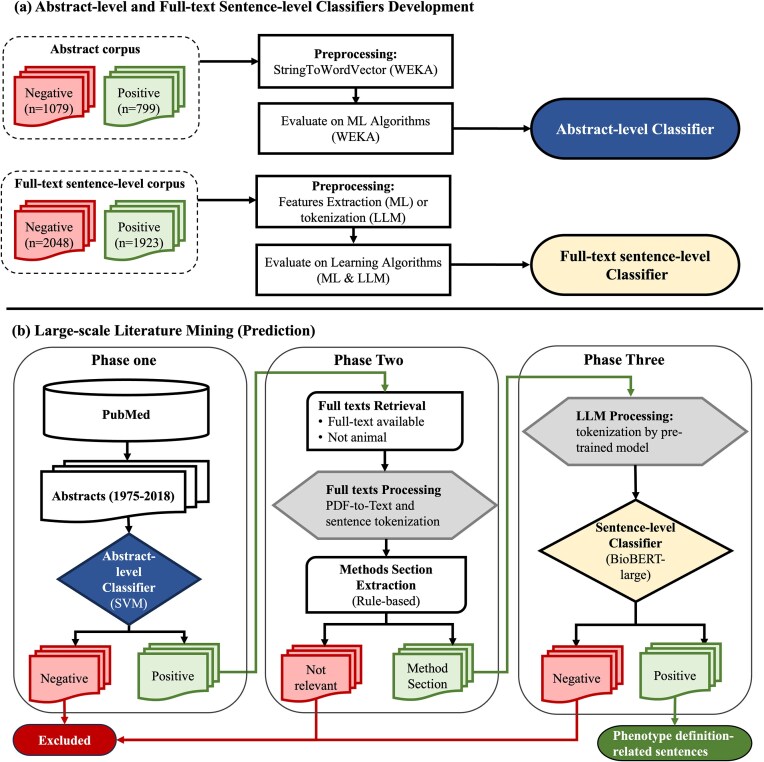
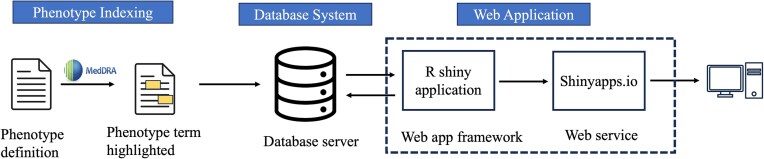
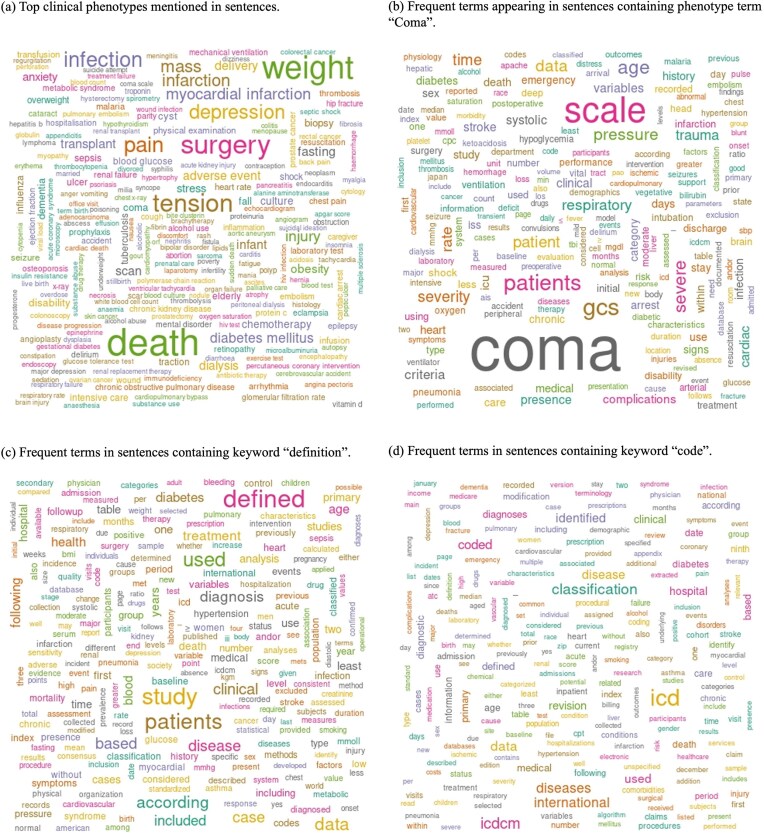
Electronic health record (EHR) phenotyping is a high-demand task because most phenotypes are not usually readily defined. The objective of this study is to develop an effective text-mining approach that automatically extracts clinical phenotype definitions-related sentences from biomedical literature. Abstract-level and full-text sentence-level classifiers were developed for clinical phenotype discovery from PubMed. We compared the performance of the abstract-level classifier on machine learning algorithms: support vector machine (SVM), logistic regression (LR), naïve Bayes, and decision tree. SVM classifier showed the best performance (F-measure = 98%) in identifying clinical phenotype-relevant abstracts. It predicted 459 406 clinical phenotype-related abstracts. For the full-text sentence-level classifier, we compared the performance of SVM, LR, naïve Bayes, decision trees, convolutional neural networks, Bidirectional Encoder Representations from Transformers (BERT), and Bidirectional Encoder Representations from Transformers for Biomedical Text Mining (BioBERT). BioBERT model was the best performer among the full-text sentence-level classifiers (F-measure = 91%). We used these two optimal classifiers for large-scale screening of the PubMed database, starting with abstract retrieval and followed by predicting clinical phenotype-related sentences from full texts. The large-scale screening predicted over two million clinical phenotype-related sentences. Lastly, we developed a knowledgebase using positively predicted sentences, allowing users to query clinical phenotype-related sentences with a phenotype term of interest. The Clinical Phenotype Knowledgebase (CliPheKB) enables users to search for clinical phenotype terms and retrieve sentences related to a specific clinical phenotype of interest (https://cliphekb.shinyapps.io/phenotype-main/). Building upon prior methods, we developed a text mining pipeline to automatically extract clinical phenotype definition-related sentences from the literature. This high-throughput phenotyping approach is generalizable and scalable, and it is complementary to existing EHR phenotyping methods.
期刊介绍:
Huge volumes of primary data are archived in numerous open-access databases, and with new generation technologies becoming more common in laboratories, large datasets will become even more prevalent. The archiving, curation, analysis and interpretation of all of these data are a challenge. Database development and biocuration are at the forefront of the endeavor to make sense of this mounting deluge of data.
Database: The Journal of Biological Databases and Curation provides an open access platform for the presentation of novel ideas in database research and biocuration, and aims to help strengthen the bridge between database developers, curators, and users.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


