Fabio Dennstädt, Max Schmerder, Elena Riggenbach, Lucas Mose, Katarina Bryjova, Nicolas Bachmann, Paul-Henry Mackeprang, Maiwand Ahmadsei, Dubravko Sinovcic, Paul Windisch, Daniel Zwahlen, Susanne Rogers, Oliver Riesterer, Martin Maffei, Eleni Gkika, Hathal Haddad, Jan Peeken, Paul Martin Putora, Markus Glatzer, Florian Putz, Daniel Hoefler, Sebastian M Christ, Irina Filchenko, Janna Hastings, Roberto Gaio, Lawrence Chiang, Daniel M Aebersold, Nikola Cihoric
{"title":"Comparative Evaluation of a Medical Large Language Model in Answering Real-World Radiation Oncology Questions: Multicenter Observational Study.","authors":"Fabio Dennstädt, Max Schmerder, Elena Riggenbach, Lucas Mose, Katarina Bryjova, Nicolas Bachmann, Paul-Henry Mackeprang, Maiwand Ahmadsei, Dubravko Sinovcic, Paul Windisch, Daniel Zwahlen, Susanne Rogers, Oliver Riesterer, Martin Maffei, Eleni Gkika, Hathal Haddad, Jan Peeken, Paul Martin Putora, Markus Glatzer, Florian Putz, Daniel Hoefler, Sebastian M Christ, Irina Filchenko, Janna Hastings, Roberto Gaio, Lawrence Chiang, Daniel M Aebersold, Nikola Cihoric","doi":"10.2196/69752","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Large language models (LLMs) hold promise for supporting clinical tasks, particularly in data-driven and technical disciplines such as radiation oncology. While prior evaluation studies have focused on examination-style settings for evaluating LLMs, their performance in real-life clinical scenarios remains unclear. In the future, LLMs might be used as general AI assistants to answer questions arising in clinical practice. It is unclear how well a modern LLM, locally executed within the infrastructure of a hospital, would answer such questions compared with clinical experts.</p><p><strong>Objective: </strong>This study aimed to assess the performance of a locally deployed, state-of-the-art medical LLM in answering real-world clinical questions in radiation oncology compared with clinical experts. The aim was to evaluate the overall quality of answers, as well as the potential harmfulness of the answers if used for clinical decision-making.</p><p><strong>Methods: </strong>Physicians from 10 departments of European hospitals collected questions arising in the clinical practice of radiation oncology. Fifty of these questions were answered by 3 senior radiation oncology experts with at least 10 years of work experience, as well as the LLM Llama3-OpenBioLLM-70B (Ankit Pal and Malaikannan Sankarasubbu). In a blinded review, physicians rated the overall answer quality on a 5-point Likert scale (quality), assessed whether an answer might be potentially harmful if used for clinical decision-making (harmfulness), and determined if responses were from an expert or the LLM (recognizability). Comparisons between clinical experts and LLMs were then made for quality, harmfulness, and recognizability.</p><p><strong>Results: </strong>There were no significant differences between the quality of the answers between LLM and clinical experts (mean scores of 3.38 vs 3.63; median 4.00, IQR 3.00-4.00 vs median 3.67, IQR 3.33-4.00; P=.26; Wilcoxon signed rank test). The answers were deemed potentially harmful in 13% of cases for the clinical experts compared with 16% of cases for the LLM (P=.63; Fisher exact test). Physicians correctly identified whether an answer was given by a clinical expert or an LLM in 78% and 72% of cases, respectively.</p><p><strong>Conclusions: </strong>A state-of-the-art medical LLM can answer real-life questions from the clinical practice of radiation oncology similarly well as clinical experts regarding overall quality and potential harmfulness. Such LLMs can already be deployed within the local hospital environment at an affordable cost. While LLMs may not yet be ready for clinical implementation as general AI assistants, the technology continues to improve at a rapid pace. Evaluation studies based on real-life situations are important to better understand the weaknesses and limitations of LLMs in clinical practice. Such studies are also crucial to define when the technology is ready for clinical implementation. Furthermore, education for health care professionals on generative AI is needed to ensure responsible clinical implementation of this transforming technology.</p>","PeriodicalId":16337,"journal":{"name":"Journal of Medical Internet Research","volume":"27 ","pages":"e69752"},"PeriodicalIF":6.0000,"publicationDate":"2025-09-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12504895/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Internet Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/69752","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Large language models (LLMs) hold promise for supporting clinical tasks, particularly in data-driven and technical disciplines such as radiation oncology. While prior evaluation studies have focused on examination-style settings for evaluating LLMs, their performance in real-life clinical scenarios remains unclear. In the future, LLMs might be used as general AI assistants to answer questions arising in clinical practice. It is unclear how well a modern LLM, locally executed within the infrastructure of a hospital, would answer such questions compared with clinical experts.
Objective: This study aimed to assess the performance of a locally deployed, state-of-the-art medical LLM in answering real-world clinical questions in radiation oncology compared with clinical experts. The aim was to evaluate the overall quality of answers, as well as the potential harmfulness of the answers if used for clinical decision-making.
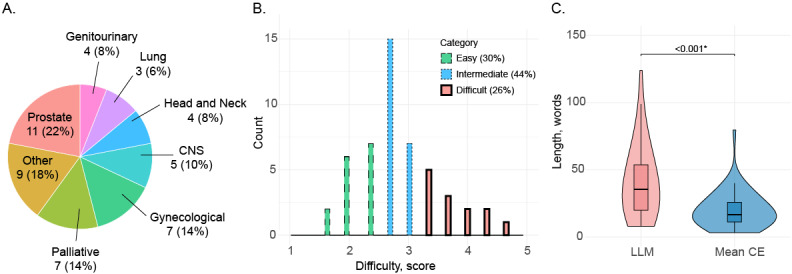
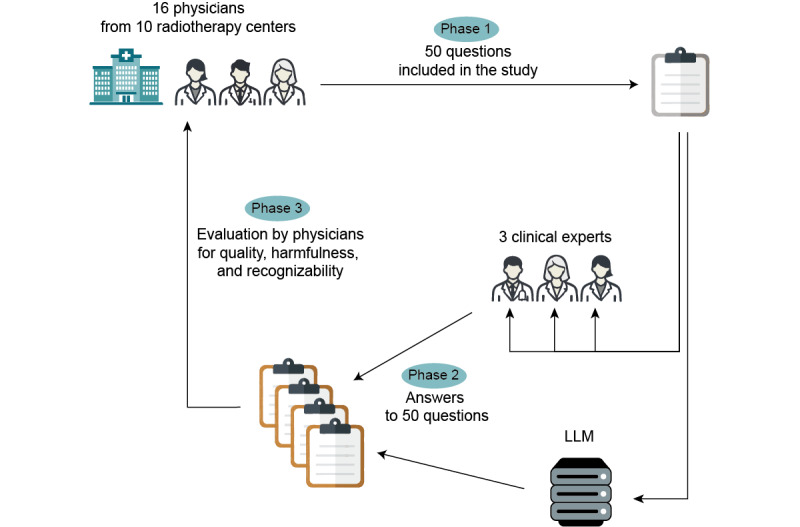
Methods: Physicians from 10 departments of European hospitals collected questions arising in the clinical practice of radiation oncology. Fifty of these questions were answered by 3 senior radiation oncology experts with at least 10 years of work experience, as well as the LLM Llama3-OpenBioLLM-70B (Ankit Pal and Malaikannan Sankarasubbu). In a blinded review, physicians rated the overall answer quality on a 5-point Likert scale (quality), assessed whether an answer might be potentially harmful if used for clinical decision-making (harmfulness), and determined if responses were from an expert or the LLM (recognizability). Comparisons between clinical experts and LLMs were then made for quality, harmfulness, and recognizability.
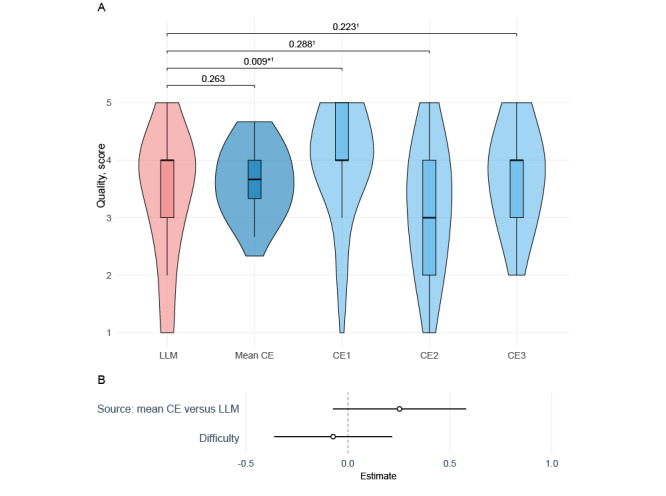
Results: There were no significant differences between the quality of the answers between LLM and clinical experts (mean scores of 3.38 vs 3.63; median 4.00, IQR 3.00-4.00 vs median 3.67, IQR 3.33-4.00; P=.26; Wilcoxon signed rank test). The answers were deemed potentially harmful in 13% of cases for the clinical experts compared with 16% of cases for the LLM (P=.63; Fisher exact test). Physicians correctly identified whether an answer was given by a clinical expert or an LLM in 78% and 72% of cases, respectively.
Conclusions: A state-of-the-art medical LLM can answer real-life questions from the clinical practice of radiation oncology similarly well as clinical experts regarding overall quality and potential harmfulness. Such LLMs can already be deployed within the local hospital environment at an affordable cost. While LLMs may not yet be ready for clinical implementation as general AI assistants, the technology continues to improve at a rapid pace. Evaluation studies based on real-life situations are important to better understand the weaknesses and limitations of LLMs in clinical practice. Such studies are also crucial to define when the technology is ready for clinical implementation. Furthermore, education for health care professionals on generative AI is needed to ensure responsible clinical implementation of this transforming technology.
期刊介绍:
The Journal of Medical Internet Research (JMIR) is a highly respected publication in the field of health informatics and health services. With a founding date in 1999, JMIR has been a pioneer in the field for over two decades.
As a leader in the industry, the journal focuses on digital health, data science, health informatics, and emerging technologies for health, medicine, and biomedical research. It is recognized as a top publication in these disciplines, ranking in the first quartile (Q1) by Impact Factor.
Notably, JMIR holds the prestigious position of being ranked #1 on Google Scholar within the "Medical Informatics" discipline.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


