High performance GPU implementation of KNN algorithm: A review
IF 1.9
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
Abstract
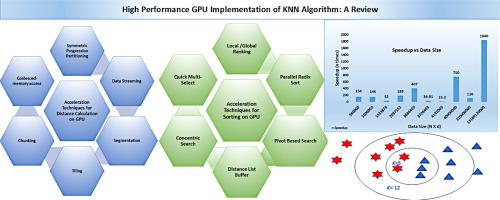
With large volumes of complex data generated by different applications, Machine Learning (ML) algorithms alone may not yield significant performance benefits on a single or multi-core CPU. Applying optimization techniques to these ML algorithms in a High-Performance Computing (HPC) environment can give considerable speedups for high-dimensional datasets. One of the most widely used classification algorithms, with applications in various domains, is the K-Nearest Neighbor (KNN). Despite its simplicity, KNN poses several challenges while handling high-dimensional data. However, the algorithm’s inherent nature presents an opportunity for parallelization. This paper reviews the optimization techniques employed by several researchers to accelerate the KNN algorithm on a GPU platform. The study reveals that techniques such as coalesced-memory access, tiling with shared memory, chunking, data segmentation, and pivot-based partitioning significantly contribute towards speeding up the KNN algorithm to leverage the GPU capabilities. The algorithms reviewed have performed exceptionally well on high-dimensional data with speedups up to 750x for a dual-GPU platform and up to 1840x for a multi-GPU platform. This study serves as a valuable resource for researchers examining KNN acceleration in high-performance computing environments and its applications in various fields.
KNN算法的高性能GPU实现:综述
对于由不同应用程序生成的大量复杂数据,单独的机器学习(ML)算法可能无法在单核或多核CPU上产生显着的性能优势。在高性能计算(HPC)环境中对这些ML算法应用优化技术可以为高维数据集提供相当大的加速。最广泛使用的分类算法之一是k -最近邻(KNN),它在各个领域都有应用。尽管简单,但KNN在处理高维数据时提出了几个挑战。然而,该算法的固有特性为并行化提供了机会。本文综述了几位研究者在GPU平台上加速KNN算法所采用的优化技术。研究表明,诸如合并内存访问、共享内存平铺、分块、数据分段和基于枢轴的分区等技术显著有助于加速KNN算法,以利用GPU功能。所审查的算法在高维数据上表现非常好,双gpu平台的加速高达750倍,多gpu平台的加速高达1840倍。本研究为研究人员在高性能计算环境中研究KNN加速及其在各个领域的应用提供了宝贵的资源。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


