RotCLIP: Tuning CLIP with visual adapter and textual prompts for rotation robust remote sensing image classification
IF 2.7
3区 工程技术
Q2 ENGINEERING, ELECTRICAL & ELECTRONIC
引用次数: 0
Abstract
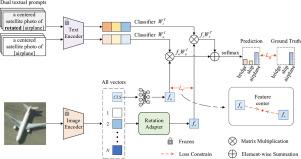
In recent years, Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success in a range of visual tasks by aligning visual and textual features. However, it remains a challenge to improve the robustness of CLIP for rotated images, especially for remote sensing images (RSIs) where objects can present various orientations. In this paper, we propose a Rotation Robust CLIP model, termed RotCLIP, to achieve the rotation robust classification of RSIs with a visual adapter and dual textual prompts. Specifically, we first compute the original and rotated visual features through the image encoder of CLIP and the proposed Rotation Adapter (Rot-Adapter). Then, we explore dual textual prompts to compute the textual features which describe original and rotated visual features through the text encoder of CLIP. Based on this, we further build a rotation robust loss to limit the distance of the two visual features. Finally, by taking advantage of the powerful image-text alignment ability of CLIP, we build a global discriminative classification loss by combining the prediction results of both original and rotated image-text features. To verify the effect of our RotCLIP, we conduct experiments on three RSI datasets, including the EuroSAT dataset used for scene classification, and the NWPU-VHR-10 and RSOD datasets used for object classification. Experimental results show that the proposed RotCLIP improves the robustness of CLIP against image rotation, outperforming several state-of-the-art methods.
RotCLIP:调整剪辑与视觉适配器和文本提示旋转鲁棒遥感图像分类
近年来,对比语言图像预训练(CLIP)通过对视觉特征和文本特征进行比对,在一系列视觉任务中取得了显著的成功。然而,提高CLIP对旋转图像的鲁棒性仍然是一个挑战,特别是对于物体可以呈现各种方向的遥感图像(rsi)。在本文中,我们提出了一个旋转鲁棒CLIP模型,称为RotCLIP,以实现旋转鲁棒分类的rsi与视觉适配器和双文本提示。具体来说,我们首先通过CLIP图像编码器和提出的旋转适配器(Rot-Adapter)计算原始和旋转的视觉特征。然后,我们探索了双文本提示,通过CLIP的文本编码器来计算描述原始和旋转视觉特征的文本特征。在此基础上,我们进一步建立了旋转鲁棒损失来限制两个视觉特征的距离。最后,利用CLIP强大的图像-文本对齐能力,结合原始和旋转图像-文本特征的预测结果,构建全局判别分类损失。为了验证RotCLIP的效果,我们在三个RSI数据集上进行了实验,包括用于场景分类的EuroSAT数据集,以及用于目标分类的NWPU-VHR-10和RSOD数据集。实验结果表明,提出的RotCLIP提高了CLIP对图像旋转的鲁棒性,优于几种最先进的方法。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Signal Processing-Image Communication
工程技术-工程:电子与电气
CiteScore
8.40
自引率
2.90%
发文量
138
审稿时长
5.2 months
期刊介绍:
Signal Processing: Image Communication is an international journal for the development of the theory and practice of image communication. Its primary objectives are the following:
To present a forum for the advancement of theory and practice of image communication.
To stimulate cross-fertilization between areas similar in nature which have traditionally been separated, for example, various aspects of visual communications and information systems.
To contribute to a rapid information exchange between the industrial and academic environments.
The editorial policy and the technical content of the journal are the responsibility of the Editor-in-Chief, the Area Editors and the Advisory Editors. The Journal is self-supporting from subscription income and contains a minimum amount of advertisements. Advertisements are subject to the prior approval of the Editor-in-Chief. The journal welcomes contributions from every country in the world.
Signal Processing: Image Communication publishes articles relating to aspects of the design, implementation and use of image communication systems. The journal features original research work, tutorial and review articles, and accounts of practical developments.
Subjects of interest include image/video coding, 3D video representations and compression, 3D graphics and animation compression, HDTV and 3DTV systems, video adaptation, video over IP, peer-to-peer video networking, interactive visual communication, multi-user video conferencing, wireless video broadcasting and communication, visual surveillance, 2D and 3D image/video quality measures, pre/post processing, video restoration and super-resolution, multi-camera video analysis, motion analysis, content-based image/video indexing and retrieval, face and gesture processing, video synthesis, 2D and 3D image/video acquisition and display technologies, architectures for image/video processing and communication.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


