LFF-POS: A linguistic fusion method to handle out-of-vocabulary words in low-resource part-of-speech tagging
IF 1.9
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
Abstract
Accurate part-of-speech (POS) tagging is needed for classroom learning evaluation in order to improve the quality of education. However, accurate POS tagging is hampered by the limited amount of training data and the high proportion of out-of-vocabulary (OOV) tokens. We present LFF-POS, a linguistic feature fusion method that overcomes these limitations for Indonesian. The procedure consists of four sequential steps: (1) tokenizing raw text; (2) extracting three complementary features; (3) merging the resulting vectors; (4) applying self-attention; and (4) training a BiLSTM sequence labeler. By combining the three features, LFF-POS improves tagging accuracy without relying on an external lexicon. Experimental results show that the combined features are able to improve the proposed model's ability to handle OOV words and achieve higher POS Tagging accuracy compared to baseline and existing methods.
OOV cannot be recognized by the model, thus reducing the accuracy of the POS Tagging model
This study aims to overcome OOV by combining linguistic features such as orthography, morphology, and characters to improve word representation
The LFF-POS has been proven to improve POS Tagging performance, especially OOV F1 Score by ±14% over baseline.
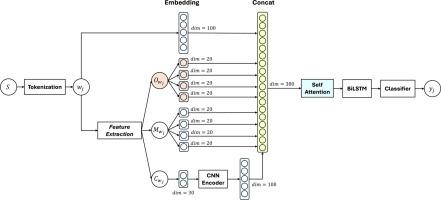
LFF-POS:一种处理低资源词性标注中词汇外词的语言融合方法
为了提高教学质量,课堂学习评价需要准确的词性标注。然而,准确的词性标注受到训练数据数量有限和词汇外(OOV)标记比例高的阻碍。我们提出了LFF-POS,一种语言特征融合方法,克服了印尼语的这些限制。该过程由四个连续步骤组成:(1)对原始文本进行标记;(2)提取三个互补特征;(3)合并得到的矢量;(4)自我关注;(4)训练一个BiLSTM序列标记器。通过结合这三个特性,LFF-POS在不依赖外部词典的情况下提高了标注准确性。实验结果表明,与基线和现有方法相比,组合特征能够提高模型对OOV词的处理能力,并获得更高的词性标注精度。该研究旨在通过结合语言特征(如正字法、形态学和字符)来改善单词表示来克服OOV。LFF-POS已被证明可以提高POS标注性能,特别是OOV F1得分比基线提高了±14%。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


