Brian Johnson, Tyler Bath, Xinyi Huang, Mark Lamm, Ashley Earles, Hyrum Eddington, Anna M Dornisch, Lily J Jih, Samir Gupta, Shailja C Shah, Kit Curtius
{"title":"Large language models for extracting histopathologic diagnoses of colorectal cancer and dysplasia from electronic health records.","authors":"Brian Johnson, Tyler Bath, Xinyi Huang, Mark Lamm, Ashley Earles, Hyrum Eddington, Anna M Dornisch, Lily J Jih, Samir Gupta, Shailja C Shah, Kit Curtius","doi":"10.1136/bmjgast-2025-001896","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>Accurate data resources are essential for impactful medical research, but available structured datasets are often incomplete or inaccurate. Recent advances in open-weight large language models (LLMs) enable more accurate data extraction from unstructured text in electronic health records (EHRs), however, thorough validation of such approaches is lacking. Our objective was to create a validated approach using LLMs for identifying histopathologic diagnoses in pathology reports from the nationwide Veterans Health Administration (VHA) database, including patients with genotype data within the Million Veteran Program (MVP) biobank.</p><p><strong>Methods: </strong>Our approach utilises search term filtering followed by simple 'yes/no' question prompts for the following phenotypes of interest: any colorectal dysplasia, high-grade dysplasia and/or colorectal adenocarcinoma (HGD/CRC) and invasive CRC. We first developed the LLM prompts using example reports from patients with inflammatory bowel disease (IBD). We then validated the approach in IBD and non-IBD by applying the fixed prompts to a separate corpus of 116 373 pathology reports generated in the VHA between 1999 and 2024. We compared model outputs to blinded manual chart review of 200-300 pathology reports for each patient cohort and diagnostic task, totalling 3816 reviewed reports, and calculated F1 scores as a balanced accuracy measure.</p><p><strong>Results: </strong>In patients with IBD in MVP, we achieved F1-scores of 96.9% (95% CI 94.0% to 99.6%) for identifying dysplasia, 93.7% (88.2%-98.4%) for identifying HGD/CRC and 98% (96.3%-99.4%) for identifying CRC. In patients without IBD in MVP, we achieved F1-scores of 99.2% (98.2%-100%) for identifying any colorectal dysplasia, 96.5% (93.0%-99.2%) for identifying HGD/CRC and 95% (92.8%-97.2%) for identifying CRC using LLM Gemma-2.</p><p><strong>Conclusion: </strong>LLMs provided excellent accuracy in extracting the diagnoses of interest from EHRs. Our validated methods generalised to unstructured pathology notes, even withstanding challenges of resource-limited computing environments. This may, therefore, be a promising approach for other clinical phenotypes given the minimal human-led development required.</p>","PeriodicalId":9235,"journal":{"name":"BMJ Open Gastroenterology","volume":"12 1","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2025-09-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12458811/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Gastroenterology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjgast-2025-001896","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"GASTROENTEROLOGY & HEPATOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: Accurate data resources are essential for impactful medical research, but available structured datasets are often incomplete or inaccurate. Recent advances in open-weight large language models (LLMs) enable more accurate data extraction from unstructured text in electronic health records (EHRs), however, thorough validation of such approaches is lacking. Our objective was to create a validated approach using LLMs for identifying histopathologic diagnoses in pathology reports from the nationwide Veterans Health Administration (VHA) database, including patients with genotype data within the Million Veteran Program (MVP) biobank.
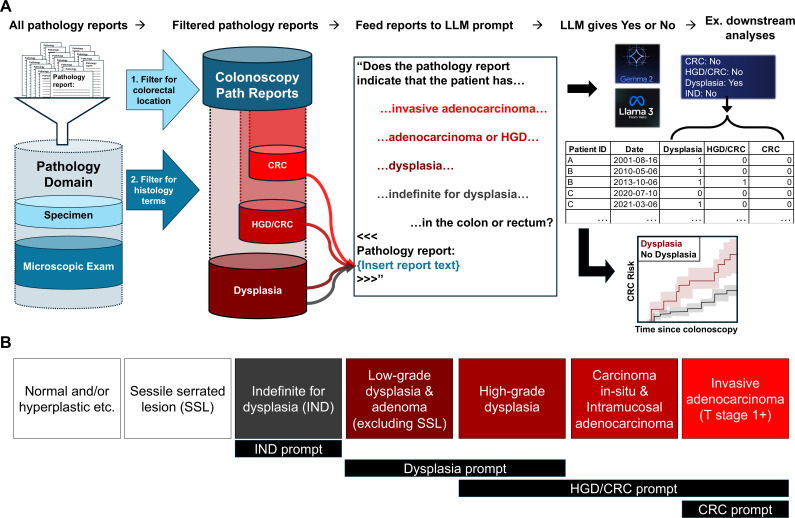
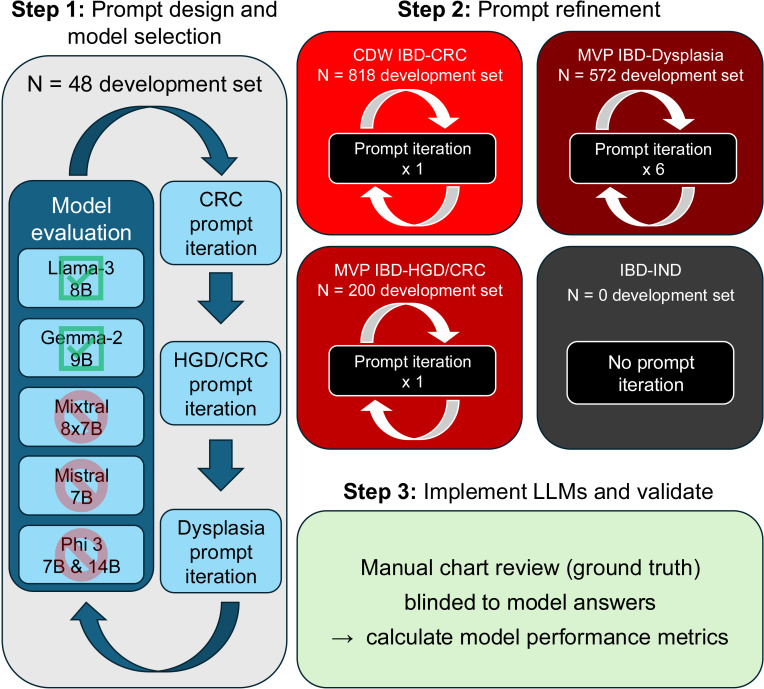
Methods: Our approach utilises search term filtering followed by simple 'yes/no' question prompts for the following phenotypes of interest: any colorectal dysplasia, high-grade dysplasia and/or colorectal adenocarcinoma (HGD/CRC) and invasive CRC. We first developed the LLM prompts using example reports from patients with inflammatory bowel disease (IBD). We then validated the approach in IBD and non-IBD by applying the fixed prompts to a separate corpus of 116 373 pathology reports generated in the VHA between 1999 and 2024. We compared model outputs to blinded manual chart review of 200-300 pathology reports for each patient cohort and diagnostic task, totalling 3816 reviewed reports, and calculated F1 scores as a balanced accuracy measure.
Results: In patients with IBD in MVP, we achieved F1-scores of 96.9% (95% CI 94.0% to 99.6%) for identifying dysplasia, 93.7% (88.2%-98.4%) for identifying HGD/CRC and 98% (96.3%-99.4%) for identifying CRC. In patients without IBD in MVP, we achieved F1-scores of 99.2% (98.2%-100%) for identifying any colorectal dysplasia, 96.5% (93.0%-99.2%) for identifying HGD/CRC and 95% (92.8%-97.2%) for identifying CRC using LLM Gemma-2.
Conclusion: LLMs provided excellent accuracy in extracting the diagnoses of interest from EHRs. Our validated methods generalised to unstructured pathology notes, even withstanding challenges of resource-limited computing environments. This may, therefore, be a promising approach for other clinical phenotypes given the minimal human-led development required.
期刊介绍:
BMJ Open Gastroenterology is an online-only, peer-reviewed, open access gastroenterology journal, dedicated to publishing high-quality medical research from all disciplines and therapeutic areas of gastroenterology. It is the open access companion journal of Gut and is co-owned by the British Society of Gastroenterology. The journal publishes all research study types, from study protocols to phase I trials to meta-analyses, including small or specialist studies. Publishing procedures are built around continuous publication, publishing research online as soon as the article is ready.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


