SynthMedic: Utilizing large language models for synthetic discharge summary generation, correction and validation
IF 4.5
2区 医学
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
Background and Objective:
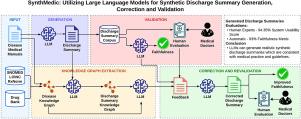
Synthetic clinical texts can improve transparency and reduce bias and costs when training and evaluating specialized language models in the medical domain. Synthetic texts are freely shareable, as they contain no real patient information, and can be customized for a specific task. The objective of this study is to develop a methodology for generating, validating, and correcting synthetic discharge summaries using LLMs without requiring any real patient data.
Methods:
The proposed approach uses an LLM to generate synthetic discharge summaries for specific diseases and standard medical references from Merck Manuals to ground the generation in internationally accepted medical practices. We validate the generated summaries using LLMs as well as by human expert validation. In addition, we propose a method for automatic correction of the generated discharge summaries using Knowledge Graphs to ensure medical factual correctness.
Results:
The conducted human expert evaluation shows that the generated synthetic discharge summaries are credible and factually accurate when provided with the medical reference context. The generated summaries achieve a System Usability Score of 94.35% based on a comprehensive rubric evaluated by medical professionals and a score of 93.65% on the Faithfulness metric evaluated by an LLM.
Conclusions:
The proposed methodology can be utilized to generate high-quality synthetic discharge summaries for various diseases. The generated synthetic corpus consists of 900 discharge summaries in English representing nine socially significant diseases and is publicly available under an open license. The community can take advantage of the corpus and proposed methodology to train complex machine learning models, helping medical professionals in their daily work without using real patient data.
SynthMedic:利用大型语言模型生成、校正和验证综合放电摘要。
背景和目的:在训练和评估医学领域的专业语言模型时,合成临床文本可以提高透明度,减少偏见和成本。合成文本可以自由共享,因为它们不包含真实的患者信息,并且可以针对特定任务进行定制。本研究的目的是开发一种方法,在不需要任何真实患者数据的情况下,使用llm生成、验证和纠正合成出院摘要。方法:提出的方法使用法学硕士生成特定疾病的综合出院摘要和默克手册中的标准医疗参考资料,以使生成符合国际公认的医疗实践。我们使用llm和人类专家验证来验证生成的摘要。此外,我们提出了一种使用知识图自动更正生成的出院摘要的方法,以确保医学事实的正确性。结果:人工专家评估表明,在提供医疗参考环境时,生成的综合出院摘要是可信的和事实准确的。根据医学专业人员评估的综合指标,生成的摘要达到了94.35%的系统可用性得分,而根据法学硕士评估的忠诚度指标,生成的摘要达到了93.65%的系统可用性得分。结论:该方法可用于生成各种疾病的高质量综合出院摘要。生成的合成语料库由900个英文出院摘要组成,代表9种具有社会意义的疾病,并在开放许可下公开提供。社区可以利用语料库和提出的方法来训练复杂的机器学习模型,在不使用真实患者数据的情况下帮助医疗专业人员进行日常工作。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Biomedical Informatics
医学-计算机:跨学科应用
CiteScore
8.90
自引率
6.70%
发文量
243
审稿时长
32 days
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


