Markus Bockhacker, Peter Martens, Clara von Münchow, Sarah Löser, Rosita Günther, Ralf Kuhlen, Olaf Kannt, Sebastian Ortleb
{"title":"Lessons Learned From Building a Data Platform for Longitudinal, Analytical Use Cases and Scaling to 77 German Hospitals: Implementation Report.","authors":"Markus Bockhacker, Peter Martens, Clara von Münchow, Sarah Löser, Rosita Günther, Ralf Kuhlen, Olaf Kannt, Sebastian Ortleb","doi":"10.2196/69853","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Increasing adoption of electronic health records (EHRs) enables research on real-world data. In Germany, this has been limited to university hospitals, and data from acute care hospitals below the university level are lacking. To address this, we used established design patterns to build a data platform that aggregates and standardizes pseudonymized EHR data with patients' consent.</p><p><strong>Objective: </strong>We report on the design and implementation of the research platform, as well as patient participation and lessons learned during the scaling of the platform, to incorporate real-world data (with participant consent) from 77 hospitals into a unified data lake.</p><p><strong>Methods: </strong>Due to variations in EHR adoption, IT infrastructure, software vendors, interface availability, and regulatory requirements, we used an agile development cycle that involves constant, incremental standardization of data. We implemented a layered lambda infrastructure built on Apache Hadoop. Decentralized connectors ensured data minimization and pseudonymization.</p><p><strong>Unlabelled: </strong>We successfully scaled our data model both vertically and horizontally in 77 hospitals. However, we encountered issues during the scaling of real-time data pipelines and IHE (Integrating the Healthcare Enterprise) interfaces. During the first 2 years, patients were asked to consent to secondary data use 1,475,244 times during inpatient admission. We registered 1,023,633 broad instances of consent (consent rate 70.2%).</p><p><strong>Conclusions: </strong>Patients are generally willing to provide consent for secondary use of their data, but obtaining consent requires considerable effort. Building a research data platform is not an end goal, but rather a necessary step in collecting and standardizing longitudinal data to enable research on real-world data. Through the combination of agile development, phased rollouts, and very high levels of automation, we have been able to achieve fast turnaround times for incorporating user feedback and are constantly improving data quality and standardization.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e69853"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12431789/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/69853","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Increasing adoption of electronic health records (EHRs) enables research on real-world data. In Germany, this has been limited to university hospitals, and data from acute care hospitals below the university level are lacking. To address this, we used established design patterns to build a data platform that aggregates and standardizes pseudonymized EHR data with patients' consent.
Objective: We report on the design and implementation of the research platform, as well as patient participation and lessons learned during the scaling of the platform, to incorporate real-world data (with participant consent) from 77 hospitals into a unified data lake.
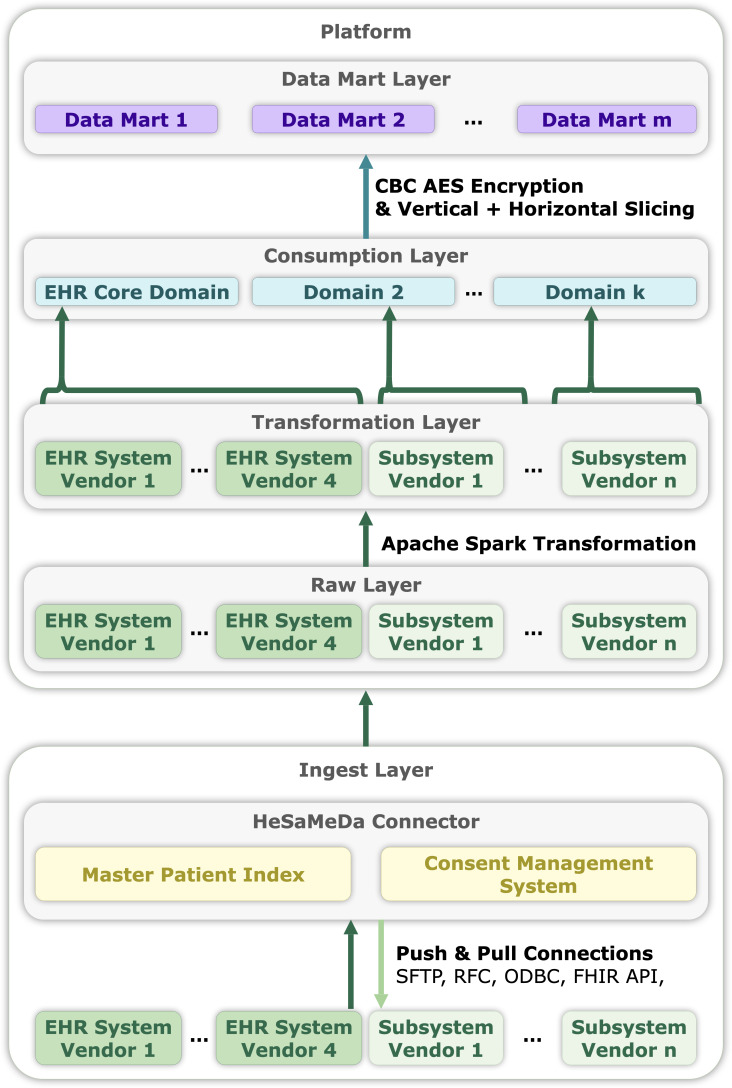
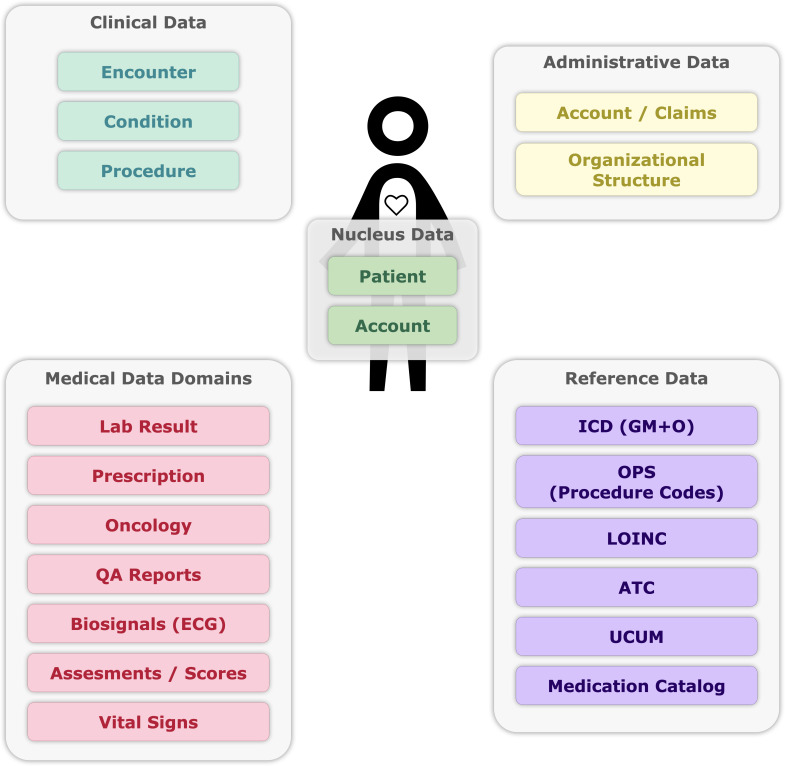
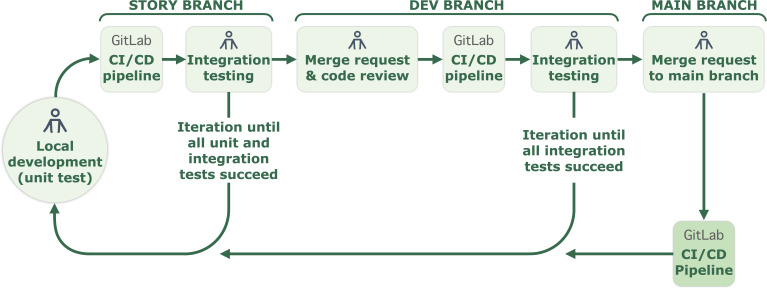
Methods: Due to variations in EHR adoption, IT infrastructure, software vendors, interface availability, and regulatory requirements, we used an agile development cycle that involves constant, incremental standardization of data. We implemented a layered lambda infrastructure built on Apache Hadoop. Decentralized connectors ensured data minimization and pseudonymization.
Unlabelled: We successfully scaled our data model both vertically and horizontally in 77 hospitals. However, we encountered issues during the scaling of real-time data pipelines and IHE (Integrating the Healthcare Enterprise) interfaces. During the first 2 years, patients were asked to consent to secondary data use 1,475,244 times during inpatient admission. We registered 1,023,633 broad instances of consent (consent rate 70.2%).
Conclusions: Patients are generally willing to provide consent for secondary use of their data, but obtaining consent requires considerable effort. Building a research data platform is not an end goal, but rather a necessary step in collecting and standardizing longitudinal data to enable research on real-world data. Through the combination of agile development, phased rollouts, and very high levels of automation, we have been able to achieve fast turnaround times for incorporating user feedback and are constantly improving data quality and standardization.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


