Simon Dahl, Martin Bøgsted, Tomer Sagi, Charles Vesteghem
{"title":"Performance of Natural Language Processing for Information Extraction From Electronic Health Records Within Cancer: Systematic Review.","authors":"Simon Dahl, Martin Bøgsted, Tomer Sagi, Charles Vesteghem","doi":"10.2196/68707","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Over the last decade, natural language processing (NLP) has provided various solutions for information extraction (IE) from textual clinical data. In recent years, the use of NLP in cancer research has gained considerable attention, with numerous studies exploring the effectiveness of various NLP techniques for identifying and extracting cancer-related entities from clinical text data.</p><p><strong>Objective: </strong>We aimed to summarize the performance differences between various NLP models for IE within the context of cancer to provide an overview of the relative performance of existing models.</p><p><strong>Methods: </strong>This systematic literature review was conducted using 3 databases (PubMed, Scopus, and Web of Science) to search for articles extracting cancer-related entities from clinical texts. In total, 33 articles were eligible for inclusion. We extracted NLP models and their performance by F1-scores. Each model was categorized into the following categories: rule-based, traditional machine learning, conditional random field-based, neural network, and bidirectional transformer (BT). The average of the performance difference for each combination of categorizations was calculated across all articles.</p><p><strong>Results: </strong>The articles covered various scenarios, with the best performance for each article ranging from 0.355 to 0.985 in F1-score. Examining the overall relative performances, the BT category outperformed every other category (average F1-score between 0.2335 and 0.0439). The percentage of articles on implementing BTs has increased over the years.</p><p><strong>Conclusions: </strong>NLP has demonstrated the ability to identify and extract cancer-related entities from unstructured textual data. Generally, more advanced models outperform less advanced ones. The BT category performed the best.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e68707"},"PeriodicalIF":3.8000,"publicationDate":"2025-09-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12431712/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/68707","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Over the last decade, natural language processing (NLP) has provided various solutions for information extraction (IE) from textual clinical data. In recent years, the use of NLP in cancer research has gained considerable attention, with numerous studies exploring the effectiveness of various NLP techniques for identifying and extracting cancer-related entities from clinical text data.
Objective: We aimed to summarize the performance differences between various NLP models for IE within the context of cancer to provide an overview of the relative performance of existing models.
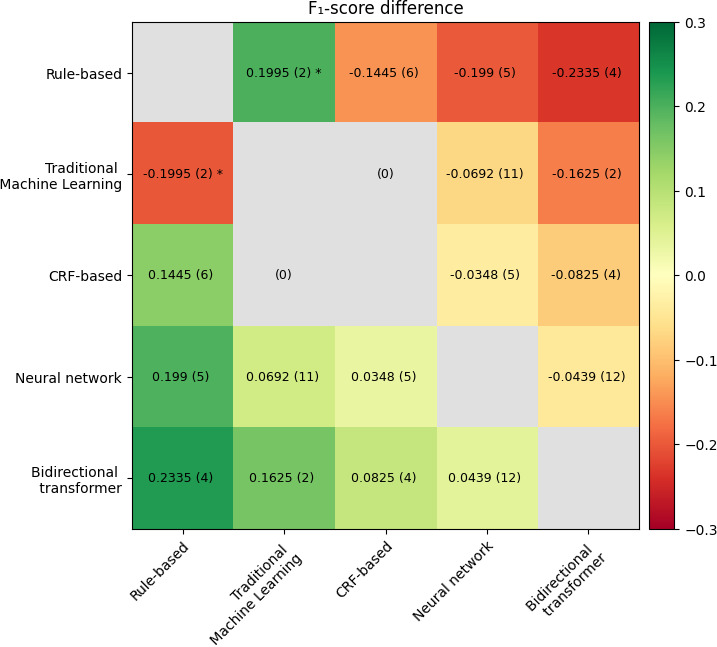
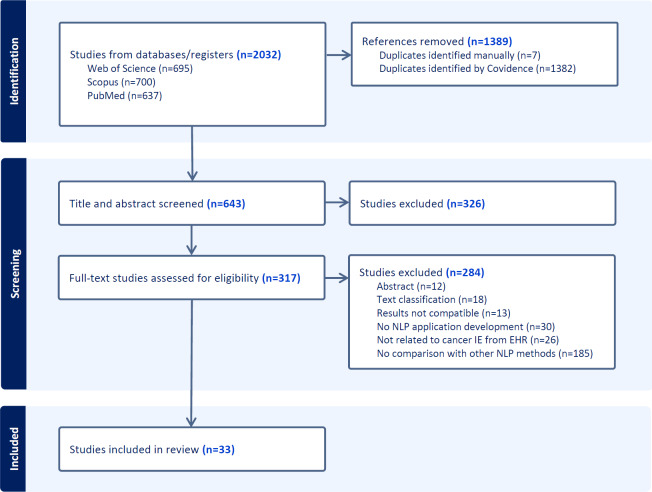
Methods: This systematic literature review was conducted using 3 databases (PubMed, Scopus, and Web of Science) to search for articles extracting cancer-related entities from clinical texts. In total, 33 articles were eligible for inclusion. We extracted NLP models and their performance by F1-scores. Each model was categorized into the following categories: rule-based, traditional machine learning, conditional random field-based, neural network, and bidirectional transformer (BT). The average of the performance difference for each combination of categorizations was calculated across all articles.
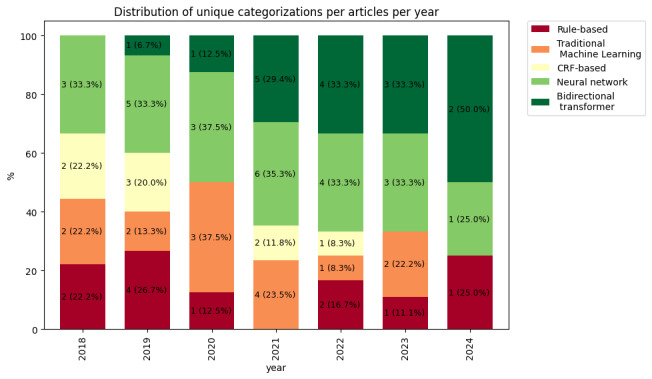
Results: The articles covered various scenarios, with the best performance for each article ranging from 0.355 to 0.985 in F1-score. Examining the overall relative performances, the BT category outperformed every other category (average F1-score between 0.2335 and 0.0439). The percentage of articles on implementing BTs has increased over the years.
Conclusions: NLP has demonstrated the ability to identify and extract cancer-related entities from unstructured textual data. Generally, more advanced models outperform less advanced ones. The BT category performed the best.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


