A systematical procedure to extracting legal entities from Indonesian judicial decisions
IF 1.9
Q2 MULTIDISCIPLINARY SCIENCES
引用次数: 0
Abstract
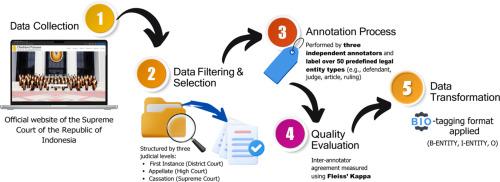
This article presents a systematic method of extracting legal entities from Indonesian judicial decisions with a well-structured named entity recognition (NER) approach. The procedure was implemented by gathering and annotating court decisions for theft cases at three court levels: first instance (2478 files), appeal (147 files), and cassation (62 files), amounting to 2687 annotated files. The data were harvested from the official website of the Supreme Court of the Republic of Indonesia using automated web scraping, followed by manual filtering for relevance and completeness.
Manual annotation was performed with the Label Studio platform by three independent annotators. Annotation consistency was considered using Fleiss' Kappa, yielding an average agreement score of 0.705 across all levels, indicating good inter-annotator reliability. The method uses a hierarchical structure and a BIO tagging scheme to tag >50 types of legal entities, including defendants, judges, legal articles, charges, and verdict decisions.
This approach is proper for text processes such as legal information extraction, classification, and legal analysis. From a legal perspective, this process will improve legal transparency and research on Indonesian judicial data.
- •Structured pipeline for gathering, filtering, and annotating Indonesian court judgments based on legal metadata and web scraping.
- •Manual annotation of 2687 court documents with annotation rules and inter-annotator agreement using Fleiss' Kappa.
- •Token-level translation and BIO tagging for >50 legal entities, enabling downstream NLP tasks such as named entity recognition.
将法律实体从印尼司法判决中分离出来的系统程序
本文提出了一种系统的方法,通过结构良好的命名实体识别(NER)方法从印度尼西亚的司法判决中提取法律实体。在一审(2478件)、上诉(147件)、原审(62件)等三级法院对盗窃案件的判决书进行了收集和注释,共计2687件注释文件。数据来自印度尼西亚共和国最高法院的官方网站,使用自动网络抓取,然后手动过滤相关性和完整性。手动注释由三个独立的注释者在Label Studio平台上执行。使用Fleiss' Kappa来考虑注释一致性,在所有水平上的平均一致性得分为0.705,表明注释者之间具有良好的可靠性。该方法使用分层结构和BIO标记方案来标记50种法律实体,包括被告、法官、法律条款、指控和判决决定。这种方法适用于法律信息提取、分类和法律分析等文本处理。从法律的角度来看,这一过程将提高法律透明度和对印度尼西亚司法数据的研究。•结构化管道,用于收集、过滤和注释基于法律元数据和网络抓取的印度尼西亚法院判决。•使用Fleiss' Kappa手动注释2687份法院文件,并使用注释规则和注释者间协议。•50个法律实体的令牌级翻译和BIO标记,支持下游NLP任务,如命名实体识别。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

MethodsX
Health Professions-Medical Laboratory Technology
CiteScore
3.60
自引率
5.30%
发文量
314
审稿时长
7 weeks
期刊介绍:
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


