{"title":"Reducing Hallucinations and Trade-Offs in Responses in Generative AI Chatbots for Cancer Information: Development and Evaluation Study.","authors":"Sota Nishisako, Takahiro Higashi, Fumihiko Wakao","doi":"10.2196/70176","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Generative artificial intelligence (AI) is increasingly used to find information. Providing accurate information is essential to support patients with cancer and their families; however, information returned by generative AIs is sometimes wrong. Returning wrong information is called hallucination. Retrieval-augmented generation (RAG), which supplements large language model (LLM) outputs with relevant external sources, has the potential to reduce hallucinations. Although RAG has been proposed as a promising technique, its real-world performance in public health communication remains underexplored.</p><p><strong>Objective: </strong>This study aimed to examine cancer information returned by generative AIs with RAG using cancer-specific information sources and general internet searches to determine whether using RAG with reliable information sources reduces the hallucination rates of generative AI chatbots.</p><p><strong>Methods: </strong>We developed 6 types of chatbots by combining 3 patterns of reference information with 2 versions of LLMs. Thus, GPT-4 and GPT-3.5 chatbots that use cancer information service (CIS) information, Google information, and no reference information (conventional chatbots) were developed. A total of 62 cancer-related questions in Japanese were compiled from public sources. All responses were generated automatically and independently reviewed by 2 experienced clinicians. The reviewers assessed the presence of hallucinations, defined as medically harmful or misinformation. We compared hallucination rates across chatbot types and calculated odds ratios (OR) using generalized linear mixed-effects models. Subgroup analyses were also performed based on whether questions were covered by CIS content.</p><p><strong>Results: </strong>For the chatbots that used information from CIS, the hallucination rates were 0% for GPT-4 and 6% for GPT-3.5, whereas those for chatbots that used information from Google were 6% and 10% for GPT-4 and GPT-3.5, respectively. For questions on information that is not issued by CIS, the hallucination rates for Google-based chatbots were 19% for GPT-4 and 35% for GPT-3.5. The hallucination rates for conventional chatbots were approximately 40%. Using reference data from Google searches generated more hallucinations than using CIS data, with an OR of 9.4 (95% CI 1.2-17.5, P<.01); the OR for the conventional chatbot was 16.1 (95% CI 3.7-50.0, P<.001). While conventional chatbots always generated a response, the RAG-based chatbots sometimes declined to answer when information was lacking. The conventional chatbots responded to all questions, but the response rate decreased (36% to 81%) for RAG-based chatbots. For questions on information not covered by CIS, the CIS chatbots did not respond, while the Google chatbots generated responses in 52% of the cases for GPT-4 and 71% for GPT-3.5.</p><p><strong>Conclusions: </strong>Using RAG with reliable information sources significantly reduces the hallucination rate of generative AI chatbots and increases the ability to admit lack of information, making them more suitable for general use, where users need to be provided with accurate information.</p>","PeriodicalId":45538,"journal":{"name":"JMIR Cancer","volume":"11 ","pages":"e70176"},"PeriodicalIF":2.7000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12425422/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Cancer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/70176","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Generative artificial intelligence (AI) is increasingly used to find information. Providing accurate information is essential to support patients with cancer and their families; however, information returned by generative AIs is sometimes wrong. Returning wrong information is called hallucination. Retrieval-augmented generation (RAG), which supplements large language model (LLM) outputs with relevant external sources, has the potential to reduce hallucinations. Although RAG has been proposed as a promising technique, its real-world performance in public health communication remains underexplored.
Objective: This study aimed to examine cancer information returned by generative AIs with RAG using cancer-specific information sources and general internet searches to determine whether using RAG with reliable information sources reduces the hallucination rates of generative AI chatbots.
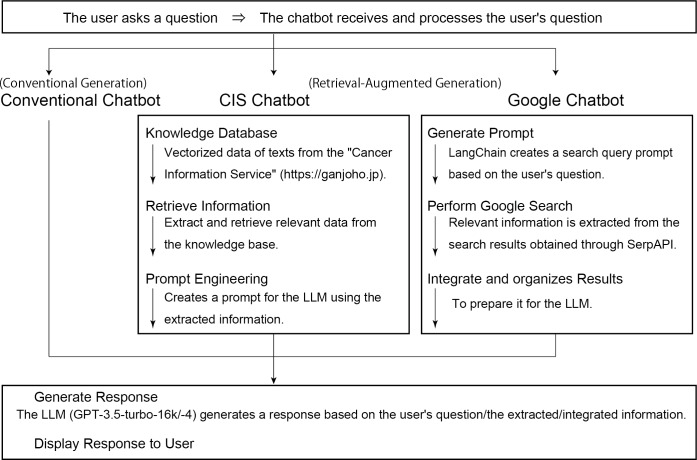
Methods: We developed 6 types of chatbots by combining 3 patterns of reference information with 2 versions of LLMs. Thus, GPT-4 and GPT-3.5 chatbots that use cancer information service (CIS) information, Google information, and no reference information (conventional chatbots) were developed. A total of 62 cancer-related questions in Japanese were compiled from public sources. All responses were generated automatically and independently reviewed by 2 experienced clinicians. The reviewers assessed the presence of hallucinations, defined as medically harmful or misinformation. We compared hallucination rates across chatbot types and calculated odds ratios (OR) using generalized linear mixed-effects models. Subgroup analyses were also performed based on whether questions were covered by CIS content.
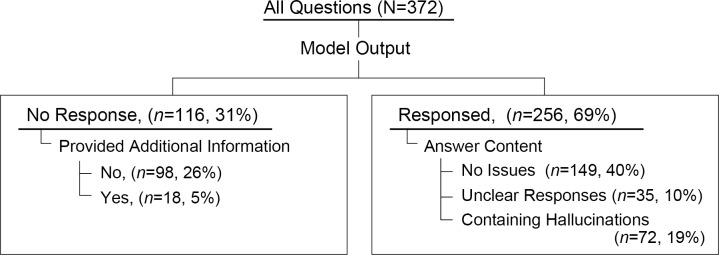
Results: For the chatbots that used information from CIS, the hallucination rates were 0% for GPT-4 and 6% for GPT-3.5, whereas those for chatbots that used information from Google were 6% and 10% for GPT-4 and GPT-3.5, respectively. For questions on information that is not issued by CIS, the hallucination rates for Google-based chatbots were 19% for GPT-4 and 35% for GPT-3.5. The hallucination rates for conventional chatbots were approximately 40%. Using reference data from Google searches generated more hallucinations than using CIS data, with an OR of 9.4 (95% CI 1.2-17.5, P<.01); the OR for the conventional chatbot was 16.1 (95% CI 3.7-50.0, P<.001). While conventional chatbots always generated a response, the RAG-based chatbots sometimes declined to answer when information was lacking. The conventional chatbots responded to all questions, but the response rate decreased (36% to 81%) for RAG-based chatbots. For questions on information not covered by CIS, the CIS chatbots did not respond, while the Google chatbots generated responses in 52% of the cases for GPT-4 and 71% for GPT-3.5.
Conclusions: Using RAG with reliable information sources significantly reduces the hallucination rate of generative AI chatbots and increases the ability to admit lack of information, making them more suitable for general use, where users need to be provided with accurate information.
背景:生成式人工智能(AI)越来越多地用于寻找信息。提供准确的信息对于支持癌症患者及其家属至关重要;然而,生成式人工智能返回的信息有时是错误的。返回错误的信息被称为幻觉。检索增强生成(RAG)用相关的外部来源补充大型语言模型(LLM)输出,具有减少幻觉的潜力。尽管RAG被认为是一种很有前途的技术,但其在公共卫生传播中的实际表现仍未得到充分探索。目的:本研究旨在通过癌症特异性信息源和一般互联网搜索来检查生成AI使用RAG返回的癌症信息,以确定使用具有可靠信息源的RAG是否会降低生成AI聊天机器人的幻觉率。方法:结合3种参考信息模式和2个版本的llm,开发出6种类型的聊天机器人。因此,开发了使用癌症信息服务(CIS)信息、谷歌信息和无参考信息(常规聊天机器人)的GPT-4和GPT-3.5聊天机器人。共有62个与癌症相关的日语问题从公共资源中汇编而成。所有应答均由2名经验丰富的临床医生自动生成并独立审查。审稿人评估了幻觉的存在,幻觉被定义为医学上有害的或错误的信息。我们比较了不同类型聊天机器人的幻觉率,并使用广义线性混合效应模型计算了比值比(OR)。还根据CIS内容是否涵盖问题进行了亚组分析。结果:对于使用CIS信息的聊天机器人,GPT-4和GPT-3.5的幻觉率分别为0%和6%,而使用GPT-4和GPT-3.5信息的聊天机器人的幻觉率分别为6%和10%。对于非CIS发布的信息的问题,基于google的聊天机器人的幻觉率在GPT-4和GPT-3.5中分别为19%和35%。传统聊天机器人的幻觉率约为40%。使用来自谷歌搜索的参考数据比使用CIS数据产生更多的幻觉,OR为9.4 (95% CI 1.2-17.5)。结论:使用具有可靠信息源的RAG显著降低了生成式AI聊天机器人的幻觉率,增加了承认信息缺失的能力,更适合于需要向用户提供准确信息的一般用途。

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


