Aditya Kommineni, Rajat Hebbar, Sarah Petrosyan, Pranali Khobragade, Sudarsana Kadiri, Miguel Arce Rentería, Jinkook Lee, Shrikanth Narayanan
{"title":"Can speech foundation models effectively identify languages in low-resource multilingual aging populations?","authors":"Aditya Kommineni, Rajat Hebbar, Sarah Petrosyan, Pranali Khobragade, Sudarsana Kadiri, Miguel Arce Rentería, Jinkook Lee, Shrikanth Narayanan","doi":"10.1121/10.0039265","DOIUrl":null,"url":null,"abstract":"<p><p>Speech foundation models (SFMs) achieve state-of-the-art results in many tasks, but their performance on elderly, multilingual speech remains underexplored. In this work, we investigate SFMs' ability to analyze multilingual speech from older adults using spoken language identification as a proxy task. We propose three key qualities for foundation models to serve multilingual aging populations: robustness to input duration, invariance to speaker demographics, and few-shot transferability in low-resource settings. Zero-shot evaluation indicates a noticeable performance drop for shorter inputs. We find that native speakers' speech consistently outperforms non-native speech across languages. Few-shot learning indicates better transferability in larger models.</p>","PeriodicalId":73538,"journal":{"name":"JASA express letters","volume":"5 9","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12434620/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JASA express letters","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1121/10.0039265","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 0
Abstract
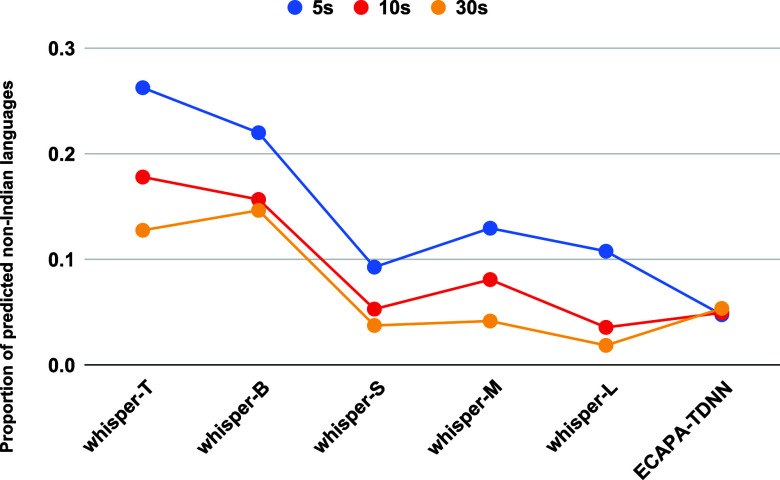
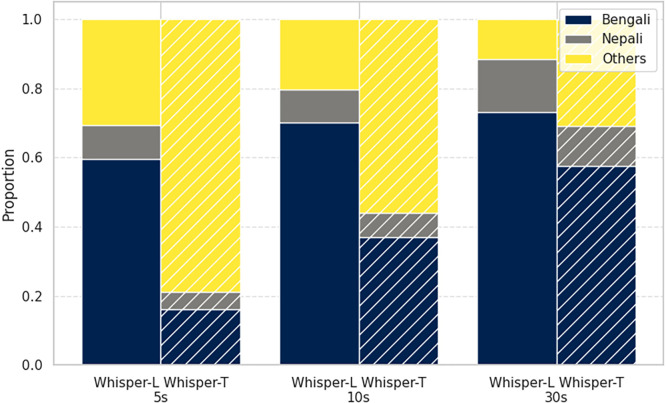
Speech foundation models (SFMs) achieve state-of-the-art results in many tasks, but their performance on elderly, multilingual speech remains underexplored. In this work, we investigate SFMs' ability to analyze multilingual speech from older adults using spoken language identification as a proxy task. We propose three key qualities for foundation models to serve multilingual aging populations: robustness to input duration, invariance to speaker demographics, and few-shot transferability in low-resource settings. Zero-shot evaluation indicates a noticeable performance drop for shorter inputs. We find that native speakers' speech consistently outperforms non-native speech across languages. Few-shot learning indicates better transferability in larger models.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


