{"title":"NFEmbed: modeling nitrogenase activity via classification and regression with pretrained protein embeddings.","authors":"Md Muhaiminul Islam Nafi, Abdullah Al Mohaimin","doi":"10.1093/bioadv/vbaf204","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Heavy usage of synthetic nitrogen fertilizers to satisfy the increasing demands for food has led to severe environmental impacts like decreasing crop yields and eutrophication. One promising alternative is using nitrogen-fixing microorganisms as biofertilizers, which use the nitrogenase enzyme. This could also be achieved by expressing a functional nitrogenase enzyme in the cells of the cereal crops.</p><p><strong>Results: </strong>In this study, we predicted microbial strains with a high potential for nitrogenase activity using machine learning techniques. Its objective was to enable the screening and ranking of potential strains based on genomic information. We explored several protein language model embeddings for this prediction task and built two stacking ensemble models. One of them, NFEmbed-C, used k-Nearest Neighbors and Random Forest as base and meta learners, respectively. The other one, NFEmbed-R, combined Decision Tree Regressor and eXtreme Gradient Boosting Regressor as base learners, with Support Vector Regressor as the meta learner. On the Test set, both NFEmbed-C and NFEmbed-R performed better than the state-of-the-art methods with improvements ranging from 0% to 11.2% and from 30% to 51%, respectively. While NFEmbed-R got a 0.783 <i>R</i> <sup>2</sup> score, 0.158 MSE, and 0.398 RMSE, NFEmbed-C acquired 0.949 sensitivity, 0.892 F1 score, and 0.784 Matthews Correlation Coefficient on the test set.</p><p><strong>Availability and implementation: </strong>We performed our analysis in Python; code is available at https://github.com/nafcoder/NFEmbed.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf204"},"PeriodicalIF":2.8000,"publicationDate":"2025-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12417089/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf204","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: Heavy usage of synthetic nitrogen fertilizers to satisfy the increasing demands for food has led to severe environmental impacts like decreasing crop yields and eutrophication. One promising alternative is using nitrogen-fixing microorganisms as biofertilizers, which use the nitrogenase enzyme. This could also be achieved by expressing a functional nitrogenase enzyme in the cells of the cereal crops.
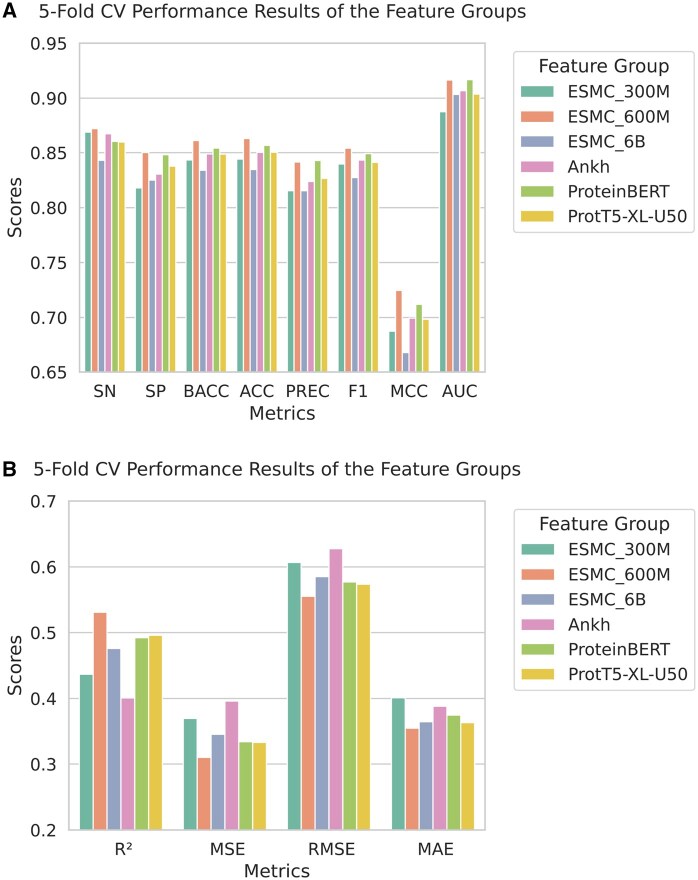
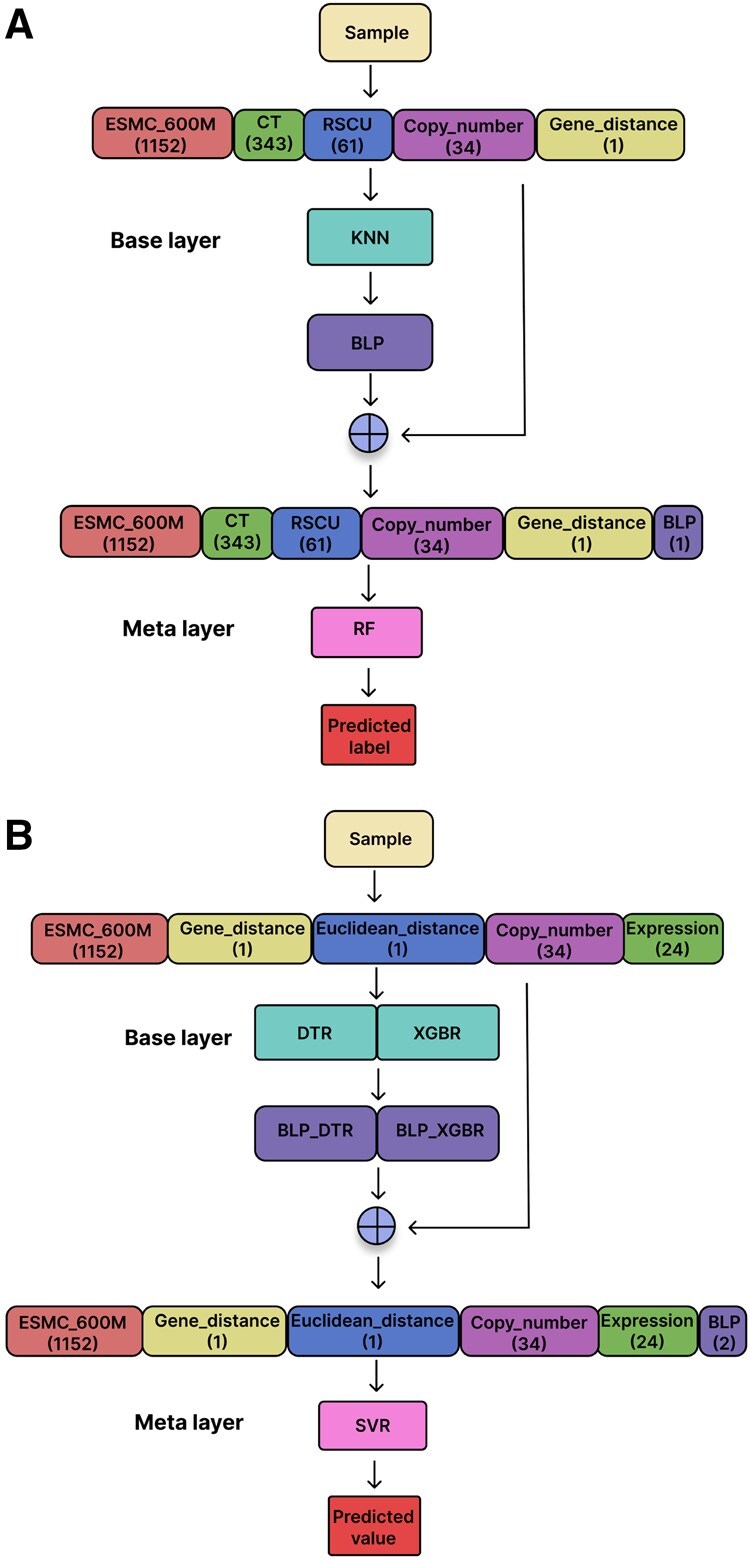
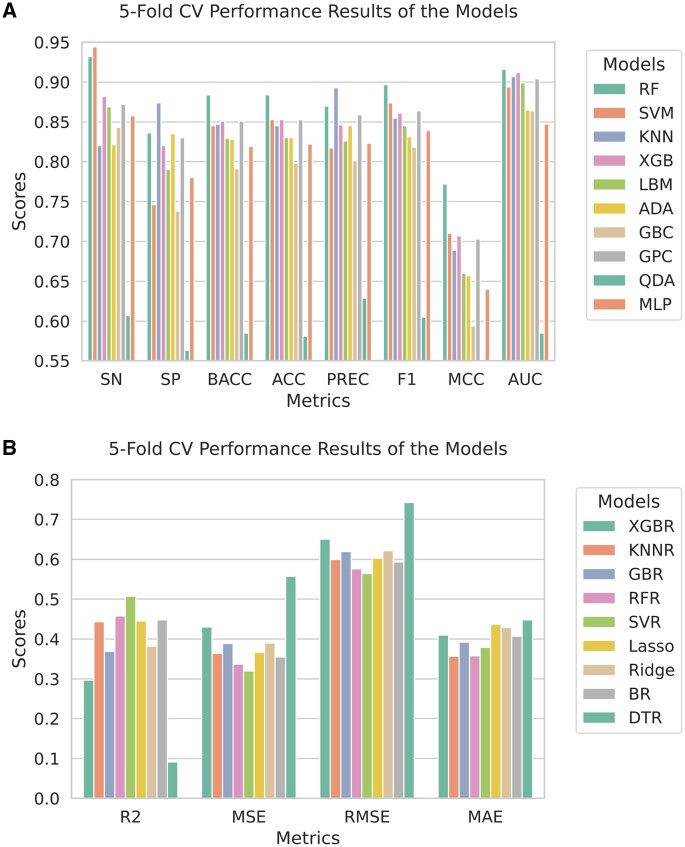
Results: In this study, we predicted microbial strains with a high potential for nitrogenase activity using machine learning techniques. Its objective was to enable the screening and ranking of potential strains based on genomic information. We explored several protein language model embeddings for this prediction task and built two stacking ensemble models. One of them, NFEmbed-C, used k-Nearest Neighbors and Random Forest as base and meta learners, respectively. The other one, NFEmbed-R, combined Decision Tree Regressor and eXtreme Gradient Boosting Regressor as base learners, with Support Vector Regressor as the meta learner. On the Test set, both NFEmbed-C and NFEmbed-R performed better than the state-of-the-art methods with improvements ranging from 0% to 11.2% and from 30% to 51%, respectively. While NFEmbed-R got a 0.783 R2 score, 0.158 MSE, and 0.398 RMSE, NFEmbed-C acquired 0.949 sensitivity, 0.892 F1 score, and 0.784 Matthews Correlation Coefficient on the test set.
Availability and implementation: We performed our analysis in Python; code is available at https://github.com/nafcoder/NFEmbed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


