Neil Jain, Caleb Gottlich, John Fisher, Travis Winston, Kristofer Matullo, Dustin Greenhill
{"title":"ChatGPT-4o is Not a Reliable Study Source for Orthopaedic Surgery Residents.","authors":"Neil Jain, Caleb Gottlich, John Fisher, Travis Winston, Kristofer Matullo, Dustin Greenhill","doi":"10.2106/JBJS.OA.25.00112","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The use of artificial intelligence platforms by medical residents as an educational resource is increasing. Within orthopaedic surgery, older Chat Generative Pre-trained Transformer (ChatGPT) models performed worse than resident physicians on practice examinations and rarely answered questions with images correctly. The newer ChatGPT-4o was designed to improve these deficiencies but has not been evaluated. This study analyzed (1) ChatGPT-4o's ability to correctly answer Orthopaedic In-Training Examination (OITE) questions and (2) the educational quality of the answer explanations that it presents to our orthopaedic surgery trainees.</p><p><strong>Methods: </strong>The 2020 to 2022 OITEs were uploaded into ChatGPT-4o. Annual score reports were used to compare the chatbot's raw score with that of ACGME-accredited orthopaedic residents. ChatGPT-4o's answer explanations were then compared with those provided by the American Academy of Orthopaedic Surgeons (AAOS) and categorized based on (1) the chatbot's answer (correct/incorrect) and (2) the chatbot's answer explanation when compared with the explanation provided by AAOS subject-matter experts (classified as consistent, disparate, or nonexistent). Overall ChatGPT-4o response quality was then simplified into 3 groups. An \"ideal\" response combined a correct answer with a consistent explanation. \"Inadequate\" responses provided a correct answer but no explanation. \"Unacceptable\" responses provided an incorrect answer or disparate explanation.</p><p><strong>Results: </strong>ChatGPT-4o scored 68.8%, 63.4%, and 70.1% on the 2020, 2021, and 2022 OITEs, respectively. These raw scores corresponded with ACGME-accredited postgraduate year-5 (PGY-5), PGY2-3, and PGY-4 resident physicians. Pediatrics and Spine were the only subspecialties whereby ChatGPT-4o consistently performed better than a junior resident (≥PGY-3). The quality of responses provided by ChatGPT-4o was ideal, inadequate, or unacceptable in 58.7%, 6.9%, and 34.4% of questions, respectively. ChatGPT-4o scored significantly lower on media-related questions when compared with nonmedia questions (60.0% versus 73.1%, p < 0.001).</p><p><strong>Conclusions: </strong>ChatGPT-4o performed inconsistently on the OITE. Moreover, the responses it provided trainees were not always ideal. Its limited performance on media-based orthopaedic surgery questions also persisted. The use of ChatGPT by resident physicians while studying orthopaedic surgery concepts remains unvalidated.</p><p><strong>Level of evidence: </strong>Level IV. See Instructions for Authors for a complete description of levels of evidence.</p>","PeriodicalId":36492,"journal":{"name":"JBJS Open Access","volume":"10 3","pages":""},"PeriodicalIF":3.8000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12417002/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JBJS Open Access","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2106/JBJS.OA.25.00112","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The use of artificial intelligence platforms by medical residents as an educational resource is increasing. Within orthopaedic surgery, older Chat Generative Pre-trained Transformer (ChatGPT) models performed worse than resident physicians on practice examinations and rarely answered questions with images correctly. The newer ChatGPT-4o was designed to improve these deficiencies but has not been evaluated. This study analyzed (1) ChatGPT-4o's ability to correctly answer Orthopaedic In-Training Examination (OITE) questions and (2) the educational quality of the answer explanations that it presents to our orthopaedic surgery trainees.
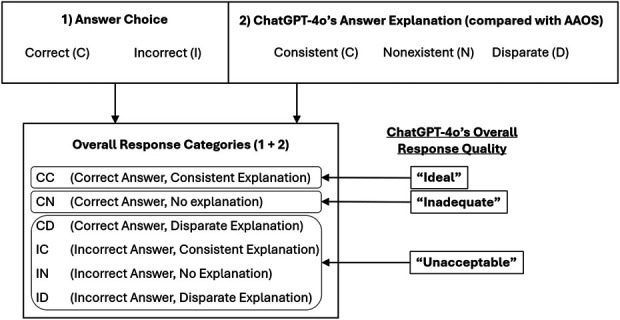
Methods: The 2020 to 2022 OITEs were uploaded into ChatGPT-4o. Annual score reports were used to compare the chatbot's raw score with that of ACGME-accredited orthopaedic residents. ChatGPT-4o's answer explanations were then compared with those provided by the American Academy of Orthopaedic Surgeons (AAOS) and categorized based on (1) the chatbot's answer (correct/incorrect) and (2) the chatbot's answer explanation when compared with the explanation provided by AAOS subject-matter experts (classified as consistent, disparate, or nonexistent). Overall ChatGPT-4o response quality was then simplified into 3 groups. An "ideal" response combined a correct answer with a consistent explanation. "Inadequate" responses provided a correct answer but no explanation. "Unacceptable" responses provided an incorrect answer or disparate explanation.
Results: ChatGPT-4o scored 68.8%, 63.4%, and 70.1% on the 2020, 2021, and 2022 OITEs, respectively. These raw scores corresponded with ACGME-accredited postgraduate year-5 (PGY-5), PGY2-3, and PGY-4 resident physicians. Pediatrics and Spine were the only subspecialties whereby ChatGPT-4o consistently performed better than a junior resident (≥PGY-3). The quality of responses provided by ChatGPT-4o was ideal, inadequate, or unacceptable in 58.7%, 6.9%, and 34.4% of questions, respectively. ChatGPT-4o scored significantly lower on media-related questions when compared with nonmedia questions (60.0% versus 73.1%, p < 0.001).
Conclusions: ChatGPT-4o performed inconsistently on the OITE. Moreover, the responses it provided trainees were not always ideal. Its limited performance on media-based orthopaedic surgery questions also persisted. The use of ChatGPT by resident physicians while studying orthopaedic surgery concepts remains unvalidated.
Level of evidence: Level IV. See Instructions for Authors for a complete description of levels of evidence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


