Federico M. Mione, Martin F. Luna, Lucas Kaspersetz, Peter Neubauer, Ernesto C. Martinez and M. Nicolas Cruz Bournazou
{"title":"A property graph schema for automated metadata capture, reproducibility and knowledge discovery in high-throughput bioprocess development†","authors":"Federico M. Mione, Martin F. Luna, Lucas Kaspersetz, Peter Neubauer, Ernesto C. Martinez and M. Nicolas Cruz Bournazou","doi":"10.1039/D5DD00070J","DOIUrl":null,"url":null,"abstract":"<p >Recent advances in autonomous experimentation and self-driving laboratories have drastically increased the complexity of orchestrating robotic experiments and of recording the different computational processes involved including all related metadata. Addressing this challenge requires a flexible and scalable information storage system that prioritizes the relationships between data and metadata, surpassing the limitations of traditional relational databases. To foster knowledge discovery in high-throughput bioprocess development, the computational control of the experimentation must be fully automated, with the capability to efficiently collect and manage experimental data and their integration into a knowledge base. This work proposes the adoption of graph databases integrated with a semantic structure to enable knowledge transfer between humans and machines. To this end, a property graph schema (PG-schema) has been specifically designed for high-throughput experiments in robotic platforms, focused mainly on the automation of the computational workflow used to ensure the reproducibility, reusability, and credibility of learned bioprocess models. A prototype implementation of the PG-schema and its integration with the workflow management system using simulated experiments is presented to highlight the advantages of the proposed approach in the generation of FAIR data.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 9","pages":" 2401-2422"},"PeriodicalIF":6.2000,"publicationDate":"2025-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2025/dd/d5dd00070j?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2025/dd/d5dd00070j","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
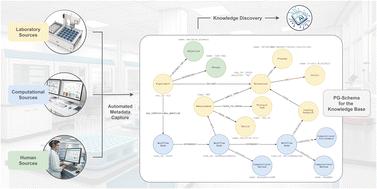
Recent advances in autonomous experimentation and self-driving laboratories have drastically increased the complexity of orchestrating robotic experiments and of recording the different computational processes involved including all related metadata. Addressing this challenge requires a flexible and scalable information storage system that prioritizes the relationships between data and metadata, surpassing the limitations of traditional relational databases. To foster knowledge discovery in high-throughput bioprocess development, the computational control of the experimentation must be fully automated, with the capability to efficiently collect and manage experimental data and their integration into a knowledge base. This work proposes the adoption of graph databases integrated with a semantic structure to enable knowledge transfer between humans and machines. To this end, a property graph schema (PG-schema) has been specifically designed for high-throughput experiments in robotic platforms, focused mainly on the automation of the computational workflow used to ensure the reproducibility, reusability, and credibility of learned bioprocess models. A prototype implementation of the PG-schema and its integration with the workflow management system using simulated experiments is presented to highlight the advantages of the proposed approach in the generation of FAIR data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


