Analog in-memory computing attention mechanism for fast and energy-efficient large language models
IF 18.3
Q1 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
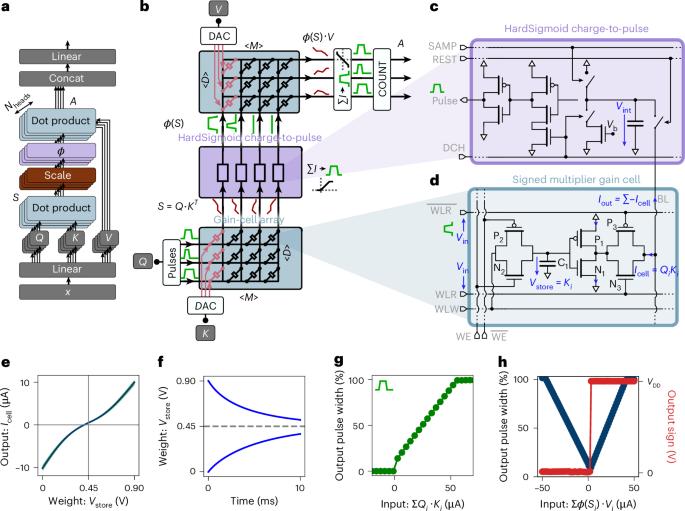
Transformer networks, driven by self-attention, are central to large language models. In generative transformers, self-attention uses cache memory to store token projections, avoiding recomputation at each time step. However, graphics processing unit (GPU)-stored projections must be loaded into static random-access memory for each new generation step, causing latency and energy bottlenecks. Here we present a custom self-attention in-memory computing architecture based on emerging charge-based memories called gain cells, which can be efficiently written to store new tokens during sequence generation and enable parallel analog dot-product computation required for self-attention. However, the analog gain-cell circuits introduce non-idealities and constraints preventing the direct mapping of pre-trained models. To circumvent this problem, we design an initialization algorithm achieving text-processing performance comparable to GPT-2 without training from scratch. Our architecture reduces attention latency and energy consumption by up to two and four orders of magnitude, respectively, compared with GPUs, marking a substantial step toward ultrafast, low-power generative transformers. Leveraging in-memory computing with emerging gain-cell devices, the authors accelerate attention—a core mechanism in large language models. They train a 1.5-billion-parameter model, achieving up to a 70,000-fold reduction in energy consumption and a 100-fold speed-up compared with GPUs.
模拟内存计算关注机制的快速和节能的大型语言模型。
由自我关注驱动的变压器网络是大型语言模型的核心。在生成式变形器中,自注意使用缓存存储器来存储标记投影,避免了每个时间步的重新计算。然而,图形处理单元(GPU)存储的投影必须在每个新生成步骤中加载到静态随机访问存储器中,从而导致延迟和能量瓶颈。在这里,我们提出了一种自定义的自关注内存计算架构,该架构基于新兴的基于电荷的存储器,称为增益单元,可以有效地编写以存储序列生成期间的新令牌,并实现自关注所需的并行模拟点积计算。然而,模拟增益单元电路引入了非理想性和限制,阻碍了预训练模型的直接映射。为了避免这个问题,我们设计了一个初始化算法,实现了与GPT-2相当的文本处理性能,而无需从头开始训练。与gpu相比,我们的架构将注意力延迟和能耗分别降低了两个和四个数量级,标志着向超快、低功耗生成变压器迈出了实质性的一步。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


